

Эксперименты. Что в результате получилось?
Zero-shot
На текущий момент у большинства пользователей уже появился GigaChat. Проще всего использовать его в формате zero-shot, подавая на вход промпт с заданием. Мы провели внутреннее тестирование этой модели (версия v.1.17.0) на задачах, описанных выше, в zero-shot с различными промптами. Ниже выходы генерации, а числовые метрики будут дальше в таблицах.
Примеры для замены англицизмов:
промпт «Перепиши этот текст без англицизмов»
Примеры для задачи рерайтинга:промпт «Перепиши текст»
Пример для упрощения текста: промпт: «Упрости текст»
Пример суммаризации небольшого текста:промпт «Сократи текст до одного предложения»
GigaChat очень неплохо справляется с задачами, особенно перефразирования и изменения стиля. Однако было замечено, что качество сильно зависит от поданной на вход инструкции (как и у большинства генеративных моделей). Это может быть и преимуществом: GigaChat не требует дообучения и может сократить текст до любого объёма в зависимости от содержания промпта. Ещё одной проблемой таких моделей является склонность к повторению, избежать этого можно либо настройкой штрафов на инференсе, либо подбором правильного промпта. Отсюда ключевой совет пользователям: с промптом нужно плотно работать, от него существенно зависит качество решения задачи.
Masked Autoregressive Flow#
Masked Autoregressive Flow (MAF; Papamakarios et al., 2017) is a type of normalizing flows, where the transformation layer is built as an autoregressive neural network. MAF is very similar to Inverse Autoregressive Flow (IAF) introduced later. See more discussion on the relationship between MAF and IAF in the next section.
Given two random variables, $\mathbf{z} \sim \pi(\mathbf{z})$ and $\mathbf{x} \sim p(\mathbf{x})$ and the probability density function $\pi(\mathbf{z})$ is known, MAF aims to learn $p(\mathbf{x})$. MAF generates each $x_i$ conditioned on the past dimensions $\mathbf{x}_{1:i-1}$.
Precisely the conditional probability is an affine transformation of $\mathbf{z}$, where the scale and shift terms are functions of the observed part of $\mathbf{x}$.
Data generation, producing a new $\mathbf{x}$:
$x_i \sim p(x_i\vert\mathbf{x}_{1:i-1}) = z_i \odot \sigma_i(\mathbf{x}_{1:i-1}) + \mu_i(\mathbf{x}_{1:i-1})\text{, where }\mathbf{z} \sim \pi(\mathbf{z})$
Density estimation, given a known $\mathbf{x}$:
$p(\mathbf{x}) = \prod_{i=1}^D p(x_i\vert\mathbf{x}_{1:i-1})$
The generation procedure is sequential, so it is slow by design. While density estimation only needs one pass the network using architecture like . The transformation function is trivial to inverse and the Jacobian determinant is easy to compute too.
Стайлайзер
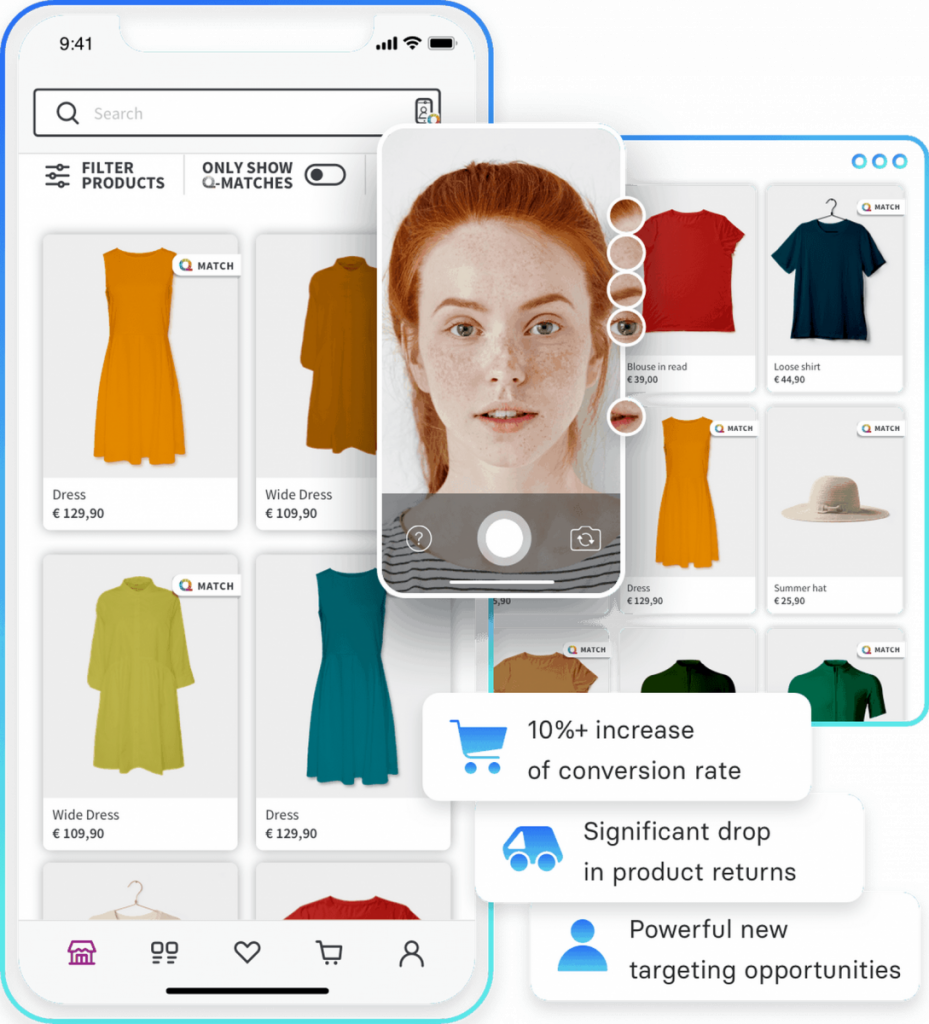 Стайлайзер
Стайлайзер
Стайлайзер — это платформа на базе искусственного интеллекта, которая предлагает цифрового помощника по покупкам. Он использует алгоритмы машинного обучения для анализа черт лица клиентов, таких как оттенок кожи и форма лица, и предоставляет очень актуальные предложения продуктов для электронной коммерции одежды. Платформа может помочь покупателям найти товары, соответствующие их стилю и предпочтениям.
Искусственный интеллект сокращает время и усилия, необходимые покупателям для поиска товаров вручную, делая процесс покупок более удобным и приятным. Используя технологию анализа лица для создания персонализированных предложений продуктов, Styleriser улучшает опыт онлайн-покупок и помогает ритейлерам увеличивать продажи.
Вообще говоря, технология ИИ позволяет массовому рынку и роскошные модные бренды рекомендовать пользователям товары, исходя из определенных модных терминов, их стиля, внешнего вида и других запросов. С помощью ИИ розничные продавцы и бренды могут предлагать решения по стилю и комбинации одежды, созданные с помощью искусственного интеллекта.
Кстати, недавно итальянский люксовый бренд Zegna введены свое приложение на базе искусственного интеллекта Zegna X. Немецкая розничная платформа Zalando также объявленный его ChatGPTПомощник по моде, который позволит покупателям более интуитивно просматривать товары.
| Прочитайте больше: 10 лучших подкастов ИИ на 2023 год |
Заключение
В последние годы в индустрии моды произошли значительные изменения: искусственный интеллект инструменты становятся все более распространенными во многих аспектах бизнеса. Десять инструментов искусственного интеллекта, описанных в этой статье, представляют собой одни из самых полезных технологических приложений, доступных модным брендам и потребителям в 2023 году. От индивидуального стиля и дизайна до оптимизации цепочки поставок — эти инструменты предлагают ценные решения для компаний, стремящихся оставаться конкурентоспособными в условиях развивающейся моды. пейзаж. По мере развития технологий мы можем ожидать, что в индустрии моды появится еще больше инструментов ИИ, которые позволят компаниям принимать более разумные и обоснованные решения и создавать более устойчивые и эффективные бизнес-модели.
FAQ
Как можно использовать ИИ в моде?
Существует несколько приложений искусственного интеллекта для индустрии моды. Бренды и частные лица могут использовать ИИ для создания дизайна, разработки инклюзивных фотосессий, настройки логистики, предложения тщательно отобранных предметов одежды и многого другого.
Какое приложение с искусственным интеллектом лучше всего подходит для дизайна одежды?
Cala и Designovel — одни из лучших приложений для дизайна одежды с искусственным интеллектом.
Используют ли модные бренды искусственный интеллект?
Модные компании и независимые дизайнеры используют искусственный интеллект для самых разных задач: от дизайна до электронной коммерции.
Читайте связанные сообщения:
<Предыдущий пост
Следующий пост >
Отбор и управление контентом
Как и в традиционном управлении знаниями, где документы загружались в платформы для обсуждений, например, Microsoft Sharepoint, в случае с генеративным ИИ, важно обеспечить высокое качество контента перед любой настройкой LLM. В некоторых случаях, как с системой Google Med-PaLM2, существуют широко доступные базы данных медицинских знаний, которые уже отобраны
В противном случае, компании должны полагаться на отбор контента человеком, чтобы гарантировать его точность, актуальность и отсутствие дубликатов. Например, в Morgan Stanley работает группа из 20 менеджеров по знаниям на Филиппинах, которые постоянно оценивают документы по различным критериям; их оценки определяют, можно ли интегрировать материал в систему GPT-4. Большинство компаний, не располагающих хорошо отобранным контентом, столкнутся с проблемами при попытке сделать это для такой цели.
Morgan Stanley также выяснил, что сохранить высокое качество знаний гораздо легче, когда авторы контента осведомлены о том, как создавать эффективные документы. Им предлагается пройти два курса: один по инструменту управления знаниями, а другой — по составлению и разметке документов. Это является частью стратегии компании по управлению контентом — систематического метода фиксации и управления ключевым цифровыми знаниями.
В Morningstar авторы контента учатся различать, какой контент эффективно взаимодействует с системой Mo, и какой нет. Они загружают свой контент в систему управления контентом, откуда он напрямую переходит в векторную базу данных, обслуживающую модель OpenAI.
LoRA
Не у всех есть возможность собрать сложный инструктивный сет и, тем более, обучить на большом объёме данных модель. Но и большой необходимости в этом нет, можно взять открытый претрейн ruGPT-3.5-13B и дообучить на своих данных один или несколько легковесных адаптеров (почитать про различные варианты адаптеров и их сравнение можно, например, в статье). Мы экспериментировали с наиболее популярным адаптером LoRA в связке с библиотекой PEFT для загрузки, квантизации и обучения модели.
Под описанные задачи мы подбирали параметры обучения адаптера, ранги, и слои, определяли степень влияния на них разных объёмов данных.
Таблица ниже показывает зависимость качества решения задачи переписывания англицизмов при фиксированном наборе слоев для разных рангов разложения в LoRA (в библиотеке PEFT, параметр r в документации PEFT)
|
rank |
successem |
successelimination_perc |
labse |
rouge-l |
BLEU |
bertscore |
chrf++ |
|
16 |
0.40 |
0.44 |
0.97 |
91.98 |
84.24 |
0.97 |
91.15 |
|
8 |
0.40 |
0.44 |
0.97 |
91.57 |
83.40 |
0.97 |
90.78 |
|
4 |
0.40 |
0.44 |
0.97 |
91.21 |
83.19 |
0.97 |
90.73 |
|
2 |
0.42 |
0.46 |
0.97 |
91.51 |
83.33 |
0.97 |
90.85 |
|
GigaChat(zero-shot) |
0.22 |
0.23 |
0.84 |
73.93 |
68.86 |
0.90 |
76.63 |
Результаты сходятся с оценками, которые представили авторы датасета Англицизмов. Заметно, что GigaChat более склонен к переписыванию входа, тогда как обученная нами LoRA вне зависимости от используемого ранга старается сохранить содержимое текста.В задаче симплификации мы также попробовали оценить влияние рангов:










|
rank |
dataset |
SARI |
bertscore |
|
16 |
public |
42.71 |
0.981 |
|
16 |
private |
42.22 |
0.979 |
|
4 |
public |
42.69 |
0.98 |
|
4 |
private |
42.17 |
0.98 |
|
GigaChat (zero-shot) |
public |
42.45 |
0.80 |
|
GigaChat (zero-shot) |
private |
42.48 |
0.80 |
Несмотря на то, что в этой задаче значительно больше обучающих данных, чем в экспериментах выше, влияние выбора ранга остаётся небольшим. При этом zero-shot на чекпоинте GigaChat показывает результаты лучше и по метрикам, и по визуальной оценке примеров.Для рерайтинга мы в дополнение к рангу разложения оценили влияние выбора раскладываемых матриц в блоках self-attention (в PEFT можно указать в параметре target_modules, подробнее в документации):
|
chrf++ |
bleu |
rouge-l |
labse |
bertscore |
|
|
LoRA_1 |
36.2 |
2.4 |
24 |
83 |
78 |
|
LoRA_2 |
34.2 |
2.3 |
23 |
81 |
77 |
|
GigaChat(zero-shot) |
40.4 |
11.3 |
29 |
84 |
78 |
Мы перепробовали множество комбинаций, лучше всего получается, когда обучающих параметров 0.20%.Задача суммаризации самая сложная из перечисленных, количество данных при этом небольшое. Поверх претрейна мы дообучили на двух сетах данных LoRA адаптеры.
обучение на данных суммаризатора ПРО
|
rouge-1 |
rouge-2 |
rouge-l |
bertscore |
meteor |
labsescore |
chrf++ |
|
0.122499 |
0.007525 |
0.111596 |
0.679537 |
0.144014 |
0.658467 |
23.507288 |
обучение на инструктивных данных
|
rouge-1 |
rouge-2 |
rouge-l |
bertscore |
meteor |
labsescore |
chrf++ |
|
0.079839 |
0.003796 |
0.075093 |
0.652626 |
0.090881 |
0.552206 |
18.094983 |
Для данной задачи оптимальное число параметров обучения варьировалось в пределах 0,14–0,29%. По метрикам видно, что выигрывает адаптер, обученный без инструкций на чистых данных суммаризатора ПРО.










Выводы по LoRA:
— В зависимости от задачи и объёма данных нужно подбирать ранг и число обучаемых параметров. Для небольшого количества примеров и простых задач ранг не сильно влияет, однако с ростом размера обучающего датасета (>5000), ранг лучше повышать. Для сопоставимого качества на конкретной задаче с SFT рекомендуется от 10000 примеров для LoRA.
— Если сравнить результаты GigaChat + LoRA c zero-shot SFT GigaChat, то адаптеры проигрывают, но для задач с небольшой вариативностью и строгим форматом заданий это неплохой вариант с минимум затрат на обучение.
Virtual photoshoots
During the pandemic, brands were often unable to bring models in for photoshoots safely. For many e-commerce stores, this posed a serious issue as model shots can make items up to 60% more likely to sell.
Unsurprisingly, some of the most popular fashion brands came up with creative solutions. The British online fashion and cosmetic retailer ASOS, for example, used AI technology to hold virtual photoshoots where six real-life models had virtual copies of the brand’s clothes mapped onto their bodies, providing shoppers with realistic garment images. It is perhaps no coincidence that the company tripled its profits from the end of 2020 to the start of 2021.
PixelRNN#
PixelRNN (Oord et al, 2016) is a deep generative model for images. The image is generated one pixel at a time and each new pixel is sampled conditional on the pixels that have been seen before.
Let’s consider an image of size $n \times n$, $\mathbf{x} = \{x_1, \dots, x_{n^2}\}$, the model starts generating pixels from the top left corner, from left to right and top to bottom (See Fig. 6).
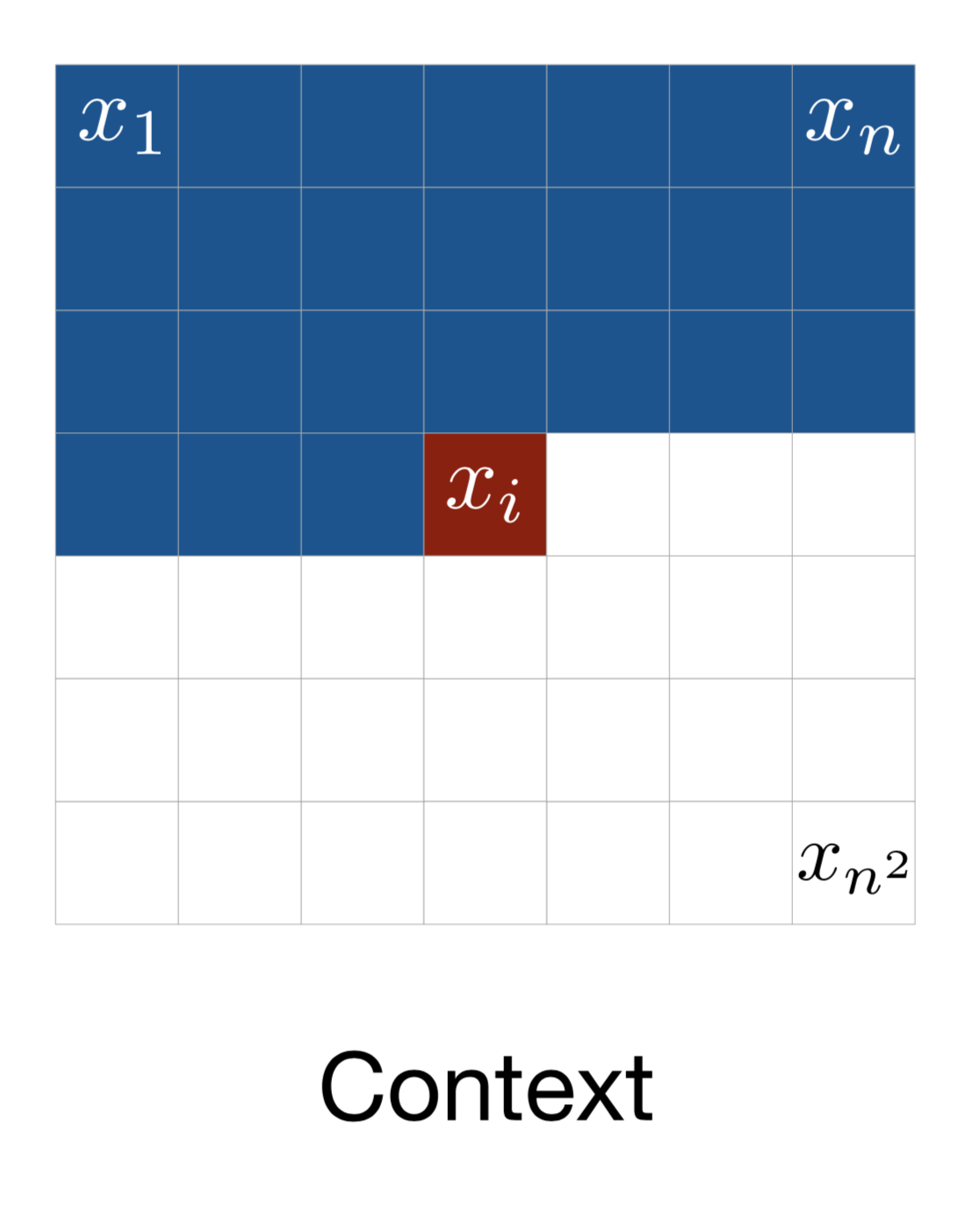 Fig. 6. The context for generating one pixel in PixelRNN. (Image source: Oord et al, 2016)
Fig. 6. The context for generating one pixel in PixelRNN. (Image source: Oord et al, 2016)
Every pixel $x_i$ is sampled from a probability distribution conditional over the the past context: pixels above it or on the left of it when in the same row. The definition of such context looks pretty arbitrary, because how visual attention is attended to an image is more flexible. Somehow magically a generative model with such a strong assumption works.
One implementation that could capture the entire context is the Diagonal BiLSTM. First, apply the skewing operation by offsetting each row of the input feature map by one position with respect to the previous row, so that computation for each row can be parallelized. Then the LSTM states are computed with respect to the current pixel and the pixels on the left.
Fig. 7. (a) PixelRNN with diagonal BiLSTM. (b) Skewing operation that offsets each row in the feature map by one with regards to the row above. (Image source: Oord et al, 2016)
$$
\begin{aligned}
\lbrack \mathbf{o}_i, \mathbf{f}_i, \mathbf{i}_i, \mathbf{g}_i \rbrack &= \sigma(\mathbf{K}^{ss} \circledast \mathbf{h}_{i-1} + \mathbf{K}^{is} \circledast \mathbf{x}_i) & \scriptstyle{\text{; }\sigma\scriptstyle{\text{ is tanh for g, but otherwise sigmoid; }}\circledast\scriptstyle{\text{ is convolution operation.}}} \\
\mathbf{c}_i &= \mathbf{f}_i \odot \mathbf{c}_{i-1} + \mathbf{i}_i \odot \mathbf{g}_i & \scriptstyle{\text{; }}\odot\scriptstyle{\text{ is elementwise product.}}\\
\mathbf{h}_i &= \mathbf{o}_i \odot \tanh(\mathbf{c}_i)
\end{aligned}
$$
where $\circledast$ denotes the convolution operation and $\odot$ is the element-wise multiplication. The input-to-state component $\mathbf{K}^{is}$ is a 1×1 convolution, while the state-to-state recurrent component is computed with a column-wise convolution $\mathbf{K}^{ss}$ with a kernel of size 2×1.
The diagonal BiLSTM layers are capable of processing an unbounded context field, but expensive to compute due to the sequential dependency between states. A faster implementation uses multiple convolutional layers without pooling to define a bounded context box. The convolution kernel is masked so that the future context is not seen, similar to . This convolution version is called PixelCNN.
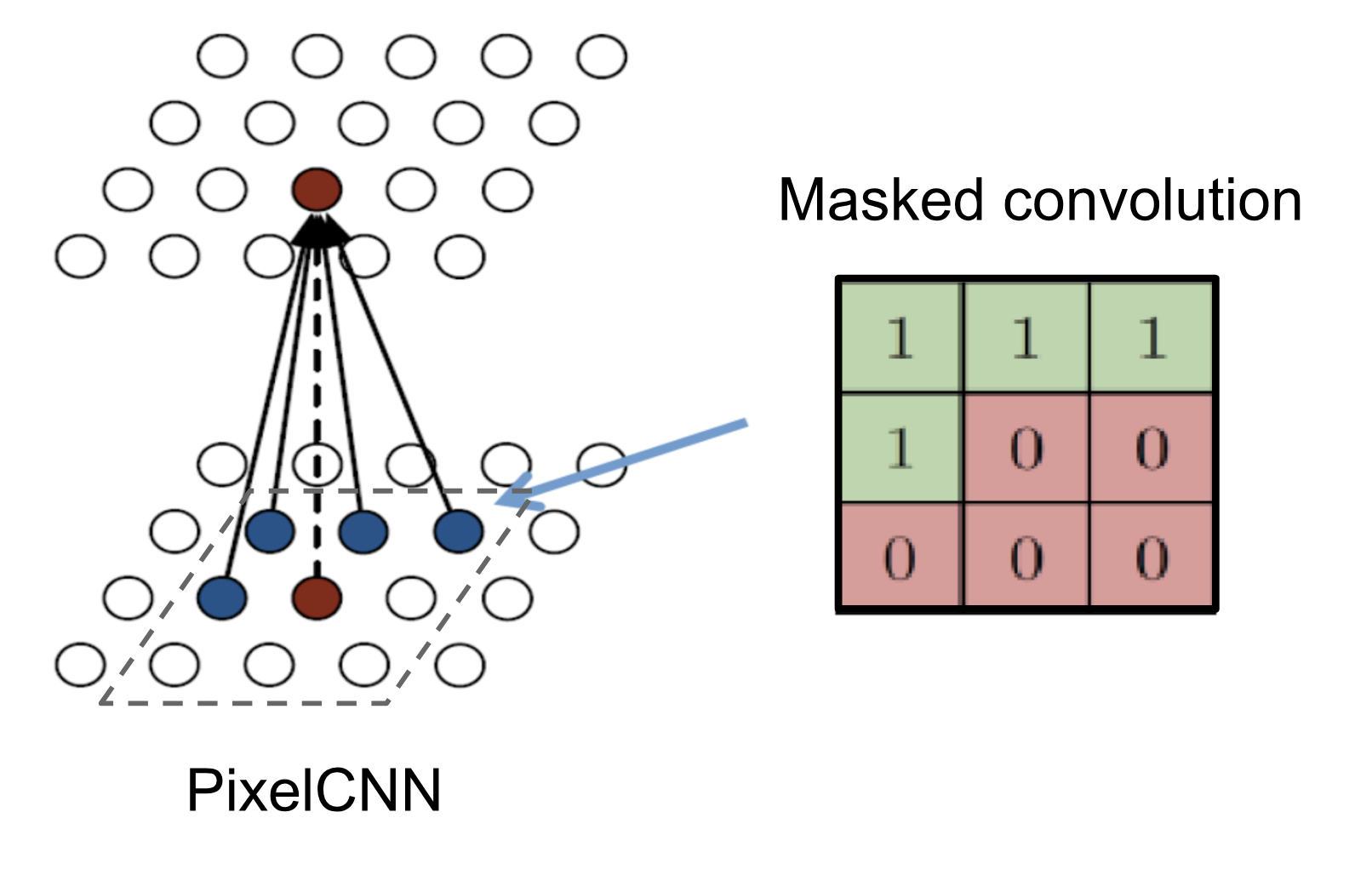 Fig. 8. PixelCNN with masked convolution constructed by an elementwise product of a mask tensor and the convolution kernel before applying it. (Image source: http://slazebni.cs.illinois.edu/spring17/lec13_advanced.pdf)
Fig. 8. PixelCNN with masked convolution constructed by an elementwise product of a mask tensor and the convolution kernel before applying it. (Image source: http://slazebni.cs.illinois.edu/spring17/lec13_advanced.pdf)
Why is generative AI important for the fashion industry?
Generative AI is important for the fashion industry as it brings many benefits. It can improve customer satisfaction and allow online retailers to bring generative products to market faster and more cost-effectively by:
- Diversifying and personalizing fashion designs
- Increasing the representation of all body types with generated models
- Creating automated digital experience in online shopping
In the fashion retail industry, where both aesthetics and consumer pleasure are important factors in fashion design and speed and novelty are crucial, generative adversarial network (GAN) offers an efficient way to generate new product designs at a low cost. Watch the video below to see the generative ability of GANs in use.
How can ChatGPT help in developing new products?
Asking ChatGPT the right questions will definitely make the product development process more productive. Try to organize your questions around the main stages of product development. Visit our Ultimate Guide to Fashion Product Development to learn about some of the most important steps in fashion product development.
Learn about the latest fashion trends
ChatGPT is an excellent tool for gaining access to a wealth of fashion information from around the world. While it cannot predict the future, it can provide the most recent fashion trends from the world’s leading fashion houses and runways.
Based on the chat GPT answers, sustainable men’s sportswear will be trending. Next, I tried asking ChatGPT about how to incorporate sustainability into my design.
Ensure that your designs are sustainable and eco-friendly
I was advised to select sustainable fabric, create a product that produces less waste and is safe, and partner with a facility that uses sustainable production procedures.
Can ChatGPT help me find a sustainable sourcing company?
Find sustainable fabric for your fashion products
It selected three top sustainable fabric suppliers, as well as some of the most popular trade shows, based on its research.
Since I’ve decided to make men’s sportswear, let’s check which sustainable sportswear material it recommends.
I like how, in addition to the fabric’s composition, it suggests checking for sustainable certifications to guarantee that the fabric satisfies environmental criteria.
Find sustainable clothing manufacturers
I’ve noticed that along the way ChatGPT also provided me with some tips on which questions to ask.
So I decided to check if it can suggest sustainable manufacturers to work with. Unfortunately, it didn’t give me any direct contacts, only tips on how to look for them.
I also wondered if it can lead me to a sustainable activewear manufacturer since I will be developing sportswear. But it just gave me a number of US brands that sell sustainable sportswear.
Find the best software for tech packs
The best feature of AI tools is their ability to perform intelligent extracts and summaries. It provided me with the latest software options for fashion tech packs and their brief description.

Check the price of the fabric and the yardage that you need
One of the sustainable materials recommended was recycled polyester. I’ll need to know the fabric cost to calculate the total cost of the garment for my costing sheet. So I asked ChatGPT.
I was also curious if it can calculate how much of that fabric I need for one sweatsuit.
Check the cost of the labor
I also asked ChatGPT how much it costs, in general, to sew a men’s sweatsuit out of this type of fabric.
How cool is that? It provides me with enough information to determine whether creating this product for my business is cost-effective.
What other materials do I need for my design?
Next, I asked ChatGPT what other materials I need for my men’s sweatsuit. It provided me with a list that will later go into my Bill of Materials. I’ve noticed that various items, such as labels, tags, and packaging, were missing. But I assumed it was because I had not inquired about how to create a retail-ready outfit.
Tip: In addition to that, you can try asking ChatGPT about which color to use for your fabric or which design elements to add to your design.
Assist with the Measurements Table
In order for my pattern maker to develop a pattern for my sweatsuit, I’ll need to include some basic measurements in my Measurement Table. Let ChatGPT assist us in determining these measurements so that we don’t overlook any.
I also wanted to see whether ChatGPT could recommend which men’s sizes I should use for my grading sheet. I was wondering if it could tell me which sizes sell most.
It provided me with some basic information about sizing and suggested doing market research. So it wasn’t very helpful with this kind of task.
Market fashion designs effectively and reach target audience
ChatGPT has proven its marketing effectiveness since its launch in late 2022. It is being used by design teams to automate simple tasks such as writing compelling product descriptions, understanding their customers’ preferences, customer support, and social media content creation.
Preparing the dataset
The first step to any ML lifecycle is to transform the dataset. In our case, we need to preprocess the CIFAR10 images so that we can feed them to our model. Hugging Face has two basic classes for data processing. Tokenizers and feature extractors.
Tokenizers
In most NLP tasks, a is our go-to solution. A tokenizer is mapping the text into tokens and then into numerical inputs that can be fed into the model. Each model comes with its own tokenizer that is based on the class.
Since we are dealing with images, we will not use a here. We will cover them more extensively in a future tutorial.
Feature Extractors
However, we will make use of another class called feature extractors. A feature extractor is usually responsible for preparing input features for models that don’t fall into the standard NLP models. They are in charge of things such as processing audio files and manipulating images. Most vision models come with a complementary feature extractor.
from transformers import ViTFeatureExtractor
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
This feature extractor will resize every image to the resolution that the model expects and normalize the channels. You can find the entire processing functionality .
Now we can define the entire processing functionality as depicted below:
defpreprocess_images(examples)
images = examples'img'
images =np.array(image, dtype=np.uint8)for image in images
images =np.moveaxis(image, source=-1, destination=)for image in images
inputs = feature_extractor(images=images)
examples'pixel_values'= inputs'pixel_values'
return examples
from datasets import Features, ClassLabel, Array3D
features = Features({
'label' ClassLabel(names='airplane','automobile','bird','cat','deer','dog','frog','horse','ship','truck'),
'img' Array3D(dtype="int64", shape=(3,32,32)),
'pixel_values' Array3D(dtype="float32", shape=(3,224,224)),
})
preprocessed_train_ds = train_ds.map(preprocess_images, batched=True, features=features)
preprocessed_val_ds = val_ds.map(preprocess_images, batched=True, features=features)
preprocessed_test_ds = test_ds.map(preprocess_images, batched=True, features=features)
A few things to note here:
-
We need to define the ourselves to make sure that the input will be in the correct format. is the main input a ViT model expects as one can inspect in the
-
We use the function to apply the transformations.
-
and are from the library.
Data collator
Another important step of the preprocessing pipeline is batching. We typically want to form batches from our dataset when training our model. Data collators are objects that help us do exactly that.
In our case, the default data collator provided from the library should be enough.
from transformers import default_data_collator data_collator = default_data_collator
We will pass the data collator as an argument to the training loop. More on that in a while.
4 Platforms to create AI models for OnlyFans
Now, you don’t need to be an expert in prompts to create AI models and generate income in OnlyFans, since there are currently several platforms that offer this type of service.
The artificial intelligences we will show below are specially trained to create NSFW content and have several tools that make it much easier to create images.
1. SoulGen
It is one of the most popular AIs for creating NSFW content. Its friendly and versatile interface allows anyone to generate AI images with total ease. In addition, it has several tools that allow you to change the pose of the models.
Also, this platform uses artificial intelligence to generate realistic models from photographs. All you have to do is upload your images and SoulGen will create a virtual model based on you. In addition, you can customize the physical appearance and personality of the model to suit your preferences.
2. PornJourney
It works with GPT-4 technology, one of the most advanced artificial intelligences nowadays. It has a simple interface, but you can set different parameters, such as body type, hairstyle, ethnicity, clothing, and background, among others. The best of all is that you can create realistic models, in the anime versions, or as 3D models.
This platform is perfect for those looking to create more explicit content. It uses AI to generate highly realistic and customizable 3D models. You can choose from hair and eye color to the size and shape of physical attributes. In addition, PornJourney offers a wide range of poses and scenarios so you can bring your fantasies to life.
In order to use PornJourney, you need to register first, and although it has a subscription, you can use this platform for free. In addition, it offers an image gallery where you can see the results of this AI without having to register.
How Good is Vicuna?
After fine-tuning Vicuna with 70K user-shared ChatGPT conversations, we discover that Vicuna becomes capable of generating more detailed and well-structured answers compared to Alpaca (see examples below), with the quality on par with ChatGPT.
However, evaluating chatbots is never a simple task.
With recent advancements in GPT-4, we are curious whether its capabilities have reached a human-like level that could enable an automated evaluation framework for benchmark generation and performance assessments.
Our initial finding indicates that GPT-4 can produce highly consistent ranks and detailed assessment when comparing chatbots’ answers (see above example of GPT-4 judgment).
Preliminary evaluations based on GPT-4, summarized in Figure 1, show that Vicuna achieves 90%* capability of Bard/ChatGPT.
While this proposed framework shows a potential to automate chatbot assessment, it is not yet a rigorous approach.
Building an evaluation system for chatbots remains an open question requiring further research. More details are provided in the evaluation section.
Figure 1. Relative Response Quality Assessed by GPT-4*
The Role of Models in the A.I. Era
Now, you must be thinking, well fashion modeling is so much more than being just a pretty face and wearing clothes. And if you’re thinking that, then you’re going in the right direction. If you’re a model that constantly explores what it means to be a model in fresh, creative and unique ways, then your job is safe. For now.
The only caveat here is that modeling is already an underpaid profession, with bad working conditions. There are grueling work hours, strict lifestyles (diets, workouts) and huge competition. Not to mention that it’s a short-lived career.










Moreover, models have to do a lot of free work to get ahead, and in their initial years, they’re usually not unique. You develop your persona and uniqueness as you go. Models of tomorrow may not have that luxury.
However, the good part is that the world still needs human models for many things. Making trends popular, creating a glam personality and aspiration, having a voice, and even being a role model are things that only humans can do. Plus the client-model relationship will still matter in many areas.
So if you’re a model, there’s no better time than now to embrace your flaws. Avoid trying to get your face to look like a typical “model”. Let your personality show through your shoots, expressions and poses. Be unique and be yourself. Work on building your personal brand.