

Советы инвесторов для VIRperson
Аналитик инвестиционного холдинга «Финам» Леонид Делицын
Специалист считает, что цифровые двойники сейчас востребованы, а само понятие может применяться не только к людям, но и к другим объектам — например, месторождениям. Но найти для них инвестиции сейчас сложно.
«Цифровые двойники исторических личностей могут найти самое разнообразное применение — в образовании, культуре, кинематографе. Однако это не самые простые индустрии с точки зрения привлечения инвестиций. Музеи, хотя там и хранятся бесценные сокровища, не являются корпорациями с миллиардами свободного кеша. Без визирования бесчисленными комиссиями самых разных департаментов они ничего не приобретут», — говорит Леонид Делицын.
Сейчас аналитик видит заинтересованность в цифровых двойниках у мошенников. Поэтому VIRperson может заработать, если пойдет обратным путем и придумает, как бороться со своим алгоритмом.
«По мере того, как Роман Душкин будет совершенствовать свою технологию, возможно, потребуется создать новую нишу отрасли кибербезопасности, которая станет продавать услуги по распознаванию двойников известных личностей, в том числе и недавно скончавшихся. Иногда так случается, что зарабатывают в итоге не на самой технологии, а на защите от её последствий», — считает Делицын.
CEO сервиса облачного видеонаблюдения и видеоаналитики Ivideon Андрей Юдников
Специалист, под управлением которого Ivideon привлекла 15 млн долларов инвестиций, рассказал, что если сами разработчики верят в VIRperson, то это уже хороший знак для инвестора. Об вере в свой проект говорит вложение личных средств.
«На текущем этапе развития проекта я бы рекомендовал не идти за деньгами, а приходить в акселератор, который позволит протестировать гипотезы монетизации и дать недостающие компетенции в тестировании продукта, поможет с нетворкингом. VIRperson следует найти профильный акселератор, который базируется на машинном обучении».
Бизнесмен заключает, что главная проблема проекта сейчас — это не поиск инвестиций, а поиск правильной монетизируемой модели.
Нейросети появились ещё в 1950-х
 Фрэнк Розенблатт работает над своим перцептроном – ранней моделью НС
Фрэнк Розенблатт работает над своим перцептроном – ранней моделью НС
Основной целью Розенблатта было не создание практической системы классификации изображений. Он пытался понять, как работает человеческий , создавая вычислительные системы, организованные по его подобию. Однако эта концепция вызвала чрезмерный энтузиазм третьих лиц.
По сути, каждый нейрон в НС представляет собой просто математическую функцию. Каждый нейрон высчитывает взвешенную сумму входных данных – чем больше вес входа, тем сильнее эти входные данные влияют на выходные данные нейрона. Затем взвешенная сумма скармливается нелинейной функции «активации» – на этом шаге НС способны моделировать сложные нелинейные явления.
Способности ранних перцептронов, с которыми экспериментировал Розенблатт – и НС в общем – проистекают из их возможности «обучаться» на примерах. НС обучают через подстройку входных весов нейронов на основе результатов работы сети с входными данными, выбранными для примера. Если сеть правильно классифицирует изображение, веса, вносящие свой вклад в правильный ответ, увеличиваются, а другие уменьшаются. Если сеть ошибается, веса подстраиваются в другом направлении.
У ранних НС Розенблатта было всего один-два обучаемых слоя. Минский и Паперт показали, что подобные НС математически неспособны моделировать сложные явления реального мира.
В итоге НС растеряли всю поддержку в 1970-х и начале 1980-х – это была часть эры «зимы ИИ».
Детали: учёт семантики
Даже если предложение составлено корректно с точки зрения синтаксиса, это не значит, что оно может соответствовать реальности. Например, предложение «Слон полетел на Луну» соответствует законам синтаксиса и грамматики, но такой сюжет может быть только в детской сказке.
Чтобы создавать соответствующие запросу тексты, ChatGPT и другие языковые модели учитывают семантику — смысловое значение единиц языка. Семантика обычно связана с какой-то моделью мира, неким скелетом, поверх которого наслаивается язык. Например, у текстов делового письма и частушки будет разная семантика.
Будущее нейросетей
Разработчики нейросетей стремятся к созданию общего ИИ (AGI). Такая система сможет успешно решать любые интеллектуальные задачи, которые способны выполнять люди.
Согласно некоторым прогнозам, AGI появится в ближайшее десятилетие, а по другим — не ранее, чем через 100 лет.
На сегодня нейросети применяют для решения узкоспециализированных задач, однако они обладают огромным потенциалом для развития.
Среди наиболее реалистичных перспектив ИИ-моделей:
- улучшение производительности, точности и эффективности моделей за счет создания новых архитектур, оптимизации обучения и использования более мощных вычислительных ресурсов;
- расширение области применения;
- использование небольшого датасета для обучения, что позволит применять модели в ситуациях с ограниченным количеством данных;
- развитие самообучающихся систем, способных непрерывно улучшать свои навыки и знания на основе реальных данных.
Специалисты также видят потенциал в интеграции нейросетей с другими технологиями, включая блокчейном. Некоторые биржи и Web3-акселераторы считают, что это слияние принесет пользу обеим отраслям, позволив каждой решить имеющиеся проблемы.
Прогнозирование и добавление одного слова за раз
Основная цель языковой модели — осмысленно продолжать цепочку слов в предложении. Но делает она это до тех пор, пока смысл похож на примеры текстов, написанных человеком.
Представим, что у нас есть текст «Самая крутая штука в нейронках — это их способность». Просматривая миллиарды страниц текста, нейронка находит все экземпляры этой фразы и изучает, какими словами они продолжаются. При этом нейронка не смотрит на текст буквально, она ищет слова, которые примерно совпадают по смыслу (об этом будет ниже).
| Текст | Следующее слово | Вероятность продолжения |
| Самая крутая штука в нейронках — это их способность | учиться | 4,5% |
| предсказывать | 3,5% | |
| создавать | 3,2% | |
| понимать | 3,1% | |
| делать | 2,9% |
Когда нейронка пишет, она оценивает текст в его текущем состоянии и рассчитывает, каким должно быть следующее слово. При этом она необязательно выбирает то слово, у которого вероятность выше. Если бы языковая модель делала так постоянно, у неё получался бы примерно одинаковый текст. Поэтому время от времени нейронка выбирает слова с более низким рейтингом.
Таким образом можно получить следующий текст:
Самая крутая штука в нейронках — это их способность
Самая крутая штука в нейронках — это их способность учиться
Самая крутая штука в нейронках — это их способность учиться на
Самая крутая штука в нейронках — это их способность учиться на своём
Самая крутая штука в нейронках — это их способность учиться на своём опыте,
Самая крутая штука в нейронках — это их способность учиться на своём опыте. Это
Самая крутая штука в нейронках — это их способность учиться на своём опыте. Это не
Почему патент Microsoft создан, чтобы давить небольшие компании
Руководитель VIRperson негативно воспринял новость о том, что Microsoft запатентовала технологию создания цифровых двойников. По его утверждению, корпорация увидела в ней перспективы и решила заняться патентной войной, прикрываясь общими формулировками.
«Предполагаю, что патент был создан для того, чтобы давить на таких, как мы. Он действительно очень осложнит нам жизнь», — говорит Роман Душкин.
Как утверждает руководитель стартапа, системы копирования личности будут доступны каждому. Душкин говорит, что у технологии могут быть трудности, потому что люди всегда боятся нового.
Зачем нужны нейросети
Организация данных в категории — наиболее частое применение нейронных сетей. В качестве примера можно привести решение о том, кому из группы людей выдать кредит, на основе анализа их личной информации, такой как возраст, финансовое положение и кредитная история. Нейронные сети используются для таких сложных вычислений, подобно человеческому мозгу.
Узнай, какие ИТ — профессии входят в ТОП-30 с доходом от 210 000 ₽/мес
Павел Симонов
Исполнительный директор Geekbrains
Команда GeekBrains совместно с международными специалистами по развитию карьеры
подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности и направления в
IT-сфере. 86% наших учеников с помощью данных материалов определились с карьерной целью на ближайшее
будущее!
Скачивайте и используйте уже сегодня:
Павел Симонов
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Получить подборку бесплатно
pdf 3,7mb
doc 1,7mb
Уже скачали 25519
Предсказание следующего хода — это способность предвидеть будущее. Например, повышение или понижение курса акций в зависимости от состояния фондовой биржи. В настоящее время нейронные сети чаще всего используются для распознавания. Они используются в Google при поиске фотографий, в камерах мобильных телефонов, когда они определяют расположение вашего лица и выделяют его, а также во многом другом.

![Нейросеть пишет текст [онлайн] | chatinfo](https://grandcapital73.ru/wp-content/uploads/d/5/0/d5098a5f1a88943917ddcbed091f7cc2.jpeg)








Третья революция: расцвет нейросетей
Несмотря на сокращение финансирования и относительное затишье, в 90-е и начале 2000-х о нейросетях не забывали. Например, был создан метод опорных векторов — техника машинного обучения с учителем для задач классификации и регрессии.
Однако в конце 2000-х всё снова изменилось. Появилисьвычислительные мощности, которых не хватало для развития нейросетей. Импульсом для этого стало развитие игровой индустрии — игры становились всё сложнее и требовали мощных видеокарт. Оказалось, что геймерские видеокарты отлично подходят для обучения искусственного интеллекта.
В 2012 году произошло знаковое событие для мира нейросетей.На конкурсе по распознаванию объектов на изображениях ImageNet LSVRP победила нейросеть AlexNet с набором данных ImageNet.
Нейросеть сделала всего 16,4% ошибок, тогда как программа, занявшая второе место, ошиблась в 26% случаев. При этом человек обычно совершает ошибки в 5% случаев.
Самое интересное, что для обучения нейросети-победителя использовали обычный компьютер с двумя видеокартами NVIDIA. На тренировки ушла примерно неделя. База данных для обучения нейросети включала 15 миллионов изображений, распределённых по 22 000 категорий. В неё входили как стандартные объекты вроде машин или домов, так и триста пород собак.
Попробуйте отличить их самостоятельно, особенно зная, что есть около 20 разновидностей терьеров ?

medium.com
Спустя 10 лет нейросети не просто распределяют фотографии по категориям, но и сами создают их по текстовым описаниям. Думаем, вы уже пользовались Midjourney, DALL-E или Stable Diffusion.
В итоге всё это привело к появлению на свет в 2020 году модели GPT-3, разработанной компанией OpenAI. GPT-3 использует технологию transformer для генерации текста. Эта модель обучается на огромном количестве текстовых данных, таких как книги, статьи, новости и интернет-контент. Она может предсказывать следующее слово в тексте на основе контекста, что позволяет ей генерировать связный текст, который выглядит так, как будто он написан человеком.
При обучении этой модели уже нельзя было ограничиться компьютером с двумя видеокартами. OpenAl использовала кластер из 35 580 GPU и 2,6 миллиона ядер процессора. А в ноябре 2022 года всему миру стал доступен сервис ChatGPT на основе GPT-3, который ознаменовал начало четвёртой революции нейросетей.
Что ждёт нас за горизонтом? Потеря рабочих мест и восстание машин? Или мир, в котором нейросети делают нашу жизнь комфортнее? В такой быстро меняющейся сфере трудно давать прогнозы. Будущее происходит на наших глазах — остаётся только следить за ним.
Где используются нейросети в современном мире
Нейронные сети помогают решать различные задачи практически во всех областях.
Их используют для распознавания и генерации изображений, речи и языка, обнаружения объектов, прогнозирования численных значений на основе входных данных и кластерного анализа.
Также ИИ-модели, в сочетании с обучением с подкреплением, применяют в играх — от настольных типа го до компьютерных вроде Dota 2 или Quake III.
Нейросети лежат в основе множества приложений и сервисов. Например, их использует Apple для понимания и генерации речи голосовым помощником Siri, а Microsoft — для перевода веб-страниц в реальном времени в браузере Bing.
Каждый поисковой запрос в Google задействует несколько ИИ-алгоритмов, чтобы понять язык вопроса и персонализировать результаты.
С помощью нейросетей AR-фильтры Snapchat и TikTok могут находить лица пользователей и накладывать на них различные эффекты. Также модели помогают Instagram искать релевантные видео для рекомендаций.
В 2022 году начали набирать популярность алгоритмы, позволяющие всем желающим создавать уникальные картины по отрывку текста. ИИ-генераторы изображений вроде DALL-E 2, Midjourney и Stable Diffusion XL до сих пор пользуются спросом и будут применятся еще долгое время.
В 2023 году сообщество стало активно разрабатывать и применять чат-ботов, базирующихся на больших языковых моделях. Технология позволяет пользователям задать вопрос, ввести запрос или подсказку и получить развернутый «почти человеческий» текстовый ответ.
Чат-боты вроде ChatGPT от OpenAI способны разговаривать на различные темы и понимать контекст, признавать ошибки, шутить и спорить.
Помимо этого, нейросети используют в различных отраслях, включая:
Как научить модель рифмовать, если она этого не хочет. Пробуем два подхода и выбираем лучший
Технологии генеративной диалоговой модели уже знакомы пользователям мобильного приложения Тинькофф. Раньше в приложении был навык болталки, который работал на ее основе: мы тестировали необходимость такой функции. Модель хорошо генерировала ответы пользователям, но не могла — и не должна была — сочинять стихи. Нам предстояло ее дообучить.
Для этого мы собрали датасет. Чтобы у модели был большой словарный запас и она могла ориентироваться в сегодняшнем контексте, мы включили в обучающую выборку не только стихи Пушкина, но и произведения современных авторов. Получилось около 60 млн стихотворений, собранных из открытых источников.
Обучив модель на этом датасете, мы получили промежуточный результат, который нас не удовлетворил. Во-первых, мы не учли некоторые моменты, когда чистили датасет, и модель нахваталась плохого. Она генерировала четверостишия с нецензурными словами, словами на иностранных языках и странными символами. Вот примеры таких стихотворений.
Во-вторых, на самом деле это нельзя было назвать стихотворениями. Мы научили модель учитывать ритм и рифму по набору правил, а не только по ударным гласным. Но в первой итерации она не научилась рифмовать. Вот пример стихотворения без рифмы:
Первую проблему мы легко решили чисткой датасета, удалив оттуда около 10 млн непригодных стихотворений. Решить проблему отсутствия рифмы оказалось сложнее. Дело в том, что мы никак не штрафовали модель за игнорирование рифм, поэтому у нее не было стимула создавать стихи. Мы провели рисерч, изучили статьи и существующие методы и выработали два собственных подхода. Сейчас подробно расскажем об обоих.
Подход первый. Подробнее о подходе можно узнать из статьи Recipes for building an open-domain chatbot. Его придумали, чтобы улучшить качество разговорных ботов. Изначально подход использовали, чтобы научить бота не выпадать из контекста диалога с пользователем и отвечать более информативными и полезными репликами. Мы решили модифицировать подход, чтобы наша модель поняла, что такое рифма, и создавала рифмующиеся строчки. Заранее скажем, что в обоих подходах мы использовали нейросеть GPT-2.
Мы разделили строки стихотворений на токены и начали специально показывать модели рифмы. В начале каждой строки мы вставляли в 20% случаев слово, которое стоит в конце предыдущей строки. А в 80% случаев — слово, которое рифмуется с последним. Таким образом модель выучила, что последнее слово должно рифмоваться с первым. В процессе инференса мы сами искали рифмы и тем самым помогали модели. Ниже — примеры стихотворений с подсказками.
Чтобы подход работал, мы написали специальный модуль поиска рифм. Прямо во время генерации стихотворения модуль подавал модели варианты. Модель могла выбрать предложенную нами рифму, а могла предложить свою на основе нашей. Этот подход какое-то время жил в виде бота в Телеграме, который сочинял стихи и нравился участникам бета-тестирования.
Подход второй. В рамках этого подхода мы с помощью GPT-2 обучили модель предсказывать следующее слово и подавали информацию о номере строки в таком формате: @LINE_11@@ буря мглою небо кроет @LINE_22@@.
Затем мы перешли к проблеме рифмы. Мы знали, что если генерировать только одну строку, вероятность получить рифму составит около 50%. А если сгенерировать десять строк, то вероятность, что появится рифма, стремится к 100%. Поэтому решили генерировать много строк и выбирать из них лучшую — ту, в которой рифма есть.
Поначалу мы думали написать отдельный классификатор для выбора лучшего варианта. Но когда посмотрели на работу модели, поняли, что в этом нет необходимости. Выкатка еще одной модели замедлила бы работу проекта. Сейчас все работает на эвристиках: они отлично справляются с задачей выбора лучшей строки и не тормозят пайплайн.
Сравнение подходов. Оба подхода обеспечили генерацию стихов. Если резюмировать, в первом подходе контроль происходил за счет того, что мы научили модель ориентироваться на рифму, которую ей подают в каждой строке, с помощью модуля поиска рифм. Во втором подходе контроль происходил за счет того, что мы заметили, что среди десяти вариантов генерации очень часто встречается строка с рифмой. Поэтому мы, по сути, контролируем генерацию, выбирая каждый раз нужную строку самостоятельно. Чтобы выбрать оптимальный подход, мы отдали результаты генерации на Толоку. Показывали людям два четверостишия и просили выбрать лучшее. Вот как выглядело задание на Толоке.

В итоге выиграл второй подход: на Толоке большинству пользователей понравились полученные с его помощью результаты.
Главная этическая проблема — кого можно воссоздавать, а кого нельзя
Если наследие Пушкина, который умер более 200 лет назад, уже стало общественным достоянием, то, к примеру, Евгений Примаков не мог дать разрешения на использование всех оставленных собой материалов для восстановления личного опыта.
По таким вопросам представители VIRperson консультируются с комитетами по этике и рабочими группами, которые специализируются на применении искусственного интеллекта. В то же время в стартапе пока не видят однозначного решения этических проблем.
По версии Душкина, если изобретённая технология будет дешёвой, то любой человек сможет оставить после себя цифровую копию. А если технология окажется дорогой, то её сможет позволить себе только высший класс.
История возникновения нейросетей
В 1943 году нейрофизиолог Уоррен Мак-Каллок и логик Уолтер Питтс опубликовали статью, где смоделировали биологическую работу органического нейрона с помощью электрических цепей. Они предположили, что нейрон можно представить как вычислительную единицу, способную принимать входные сигналы, обрабатывать их и выдавать выходные сигналы.
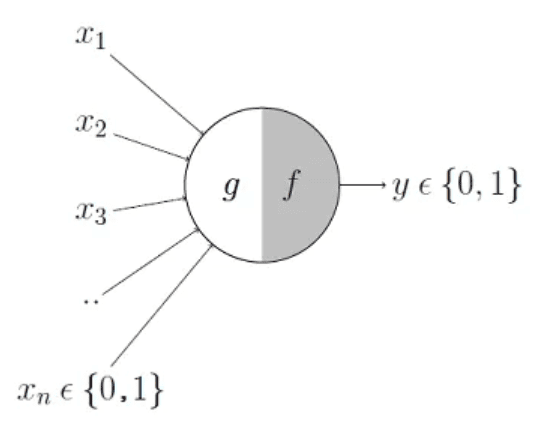
Нейрон, предложенный Мак-Каллоком—Питтсом. Данные: Towards Data Science.
В 1949 году физиолог Дональд Хебб написал книгу «Организация поведения: нейропсихологическая теория». В ней ученый отметил, что нервные пути усиливаются при каждом последующем использовании, особенно между нейронами, склонными возбуждаться одновременно.
Работа Хебба стала началом долгого пути к количественной оценке сложных процессов, происходящих в мозге.
В 1958 году вдохновленный публикацией Маккаллоха и Питтса нейрофизиолог Фрэнк Розенблатт разработал перцептрон. Именно его можно назвать первой практической реализацией нейросети.






![Написать стихи онлайн [нейросеть] | chatinfo](https://grandcapital73.ru/wp-content/uploads/5/e/9/5e9ed7b540fba4a06004891be67de6ec.jpeg)



Архитектура перцептрона.
В 1960 году ученый создал вычислительную машину «Марк I» на базе перцептрона. Это была система с простой взаимосвязью вход-выход, способная обучаться в простейших задачах.
Нейрокомпьютер «Марк I» — первая реализация перцептрона. Данные: Корнеллский университет.
В 1959 году исследователи из Стэнфордского университета Бернард Уидроу и Тед Хофф разработали первую нейронную сеть MADALINE, успешно примененную к реальной проблеме. Она используется до сих пор и помогает устранять помехи в телефонных линиях.
Эти ранние достижения породили растущую шумиху вокруг возможностей и потенциала нейросетей.
В 1958 году, на пике ажиотажа вокруг «думающих машин», издание The New York Times опубликовало статью о перспективах моделей.
В 1961 году также вышло интервью с ИИ-пионерами Джеромом Визнером, Оливером Селфриджем и Клодом Шенноном о будущем технологии.
Однако в 1969 году основатель ИИ-лаборатории MIT Марвин Мински и ее директор Сеймур Пейперт опубликовали книгу «Перцептроны». В ней ученые предположили, что однослойные модели нельзя эффективно преобразовать в многослойные.
По мнению исследователей, для оценки правильных относительных значений весов нейронов, разбросанных по слоям, на основе конечного результата потребовалось бы большое количество, если не бесконечное, итераций. Вычисления заняли бы очень много времени.
Также Мински и Пейперт изложили и другие проблемы с алгоритмами. Это привело научное сообщество и финансирующие учреждения к выводу о бесполезности дальнейших исследований в этом направлении. Началась «зима ИИ».
Интерес к технологии возобновился в 1982 году, когда ученый Джон Хопфилд представил модель с двунаправленными связями нейронов, известную как нейросеть Хопфилда. Она стала первым алгоритмом с .
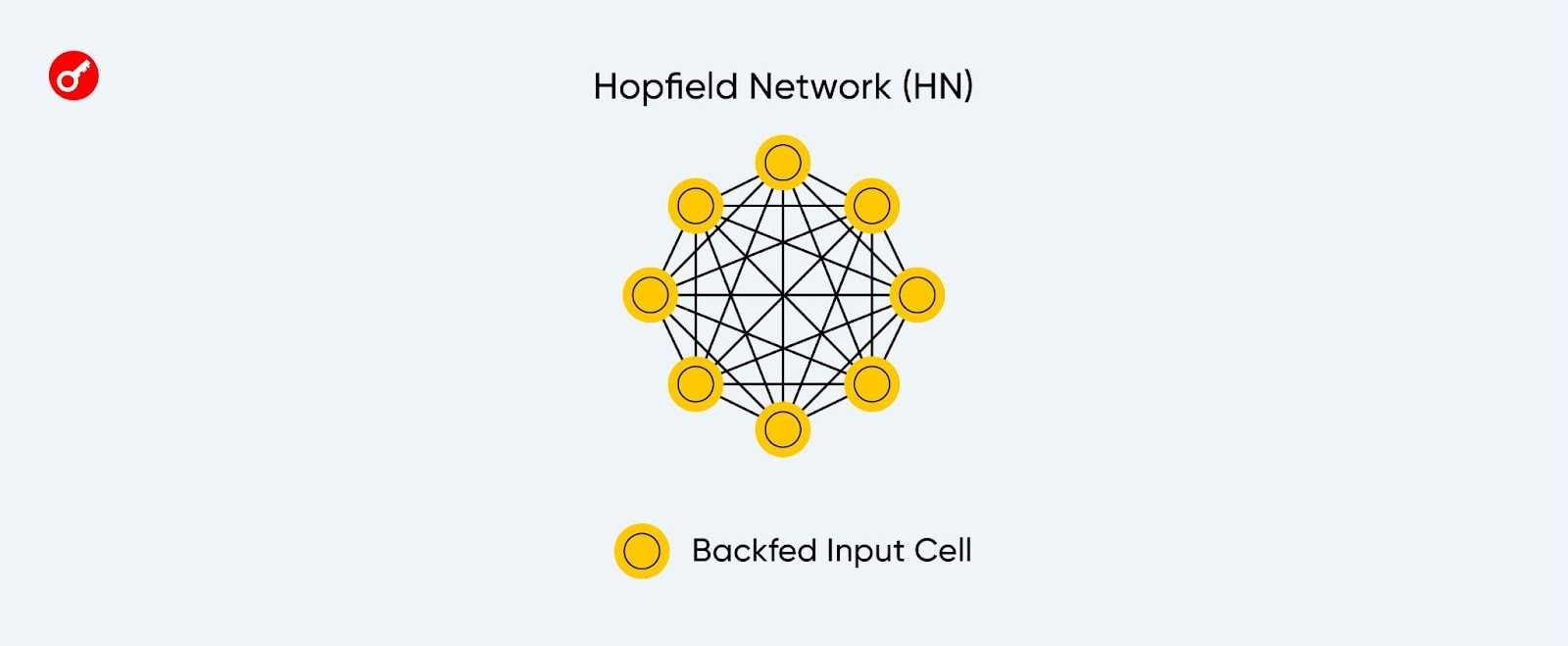
Нейронная сеть Хопфилда.
В том же году на конференции по кооперативным и конкурентным нейронным сетям Япония объявила о новой работе над моделями пятого поколения. В США опасались проиграть в гонке. Финансирование исследований возобновилось.
В 1985 году Американский институт физики учредил ежегодное собрание «Нейронные сети в вычислительной технике».
В 1987 году Институт инженеров электротехники и электроники организовал первую Международную конференцию по нейронным сетям.
В 1986 году три независимые группы исследователей заново открыли метод обратного распространения ошибки, предложенный социологом Полом Вербосом еще в 1974 году.
К 1990-м годам нейронные сети снова стали популярными, поразив воображение мира и оправдав его ожидания, если не превзойдя их.
Могут ли нейросети помочь филологам в их движении к мировому господству?
Последний вопрос мы задали персонально Борису Орехову. Сможет ли нейросеть приносить пользу филологам? Сейчас кажется, что генерация художественных текстов нейросетями нужна… просто потому что это забавно.
«Давайте сделаем, это прикольно» — неплохая мотивация, считает исследователь. Это слова, с которых могли начинаться великие проекты в истории человечества, совершенно не обязательно на этом основании что-то отметать. Что касается того, поможет ли нейросеть решить какие-то проблемы филологам, надо сначала узнать, какие проблемы есть у филологов, что именно им надо решать? Тот же Виктор Владимирович Виноградов, который написал о стиле несколько книг, совершенно не утруждал себя определением того, что такое стиль. Если это кому-то не нужно, он не определяет, а просто двигается дальше, исходя из некоторого интуитивного определения. Поэтому Борис Орехов не думает, что нужно мучительно выдавливать из себя какое-то определение. Хотя существует эпистемологический приоритет определения, при котором считается, что мы не можем что-то знать, если мы не знаем определения этого чего-то. Но кажется, что философия XX века, в частности Витгенштейн, избавили нас от необходимости следовать этому эпистемическому приоритету определения. Поэтому кажется, что нейросети нас не подталкивают к этому.
И кажется, благодаря нейросетям мы не узнаем чего-то нового о художественном творчестве. Это очень давний стереотип, что если мы воспроизведём некоторый сложный синтетический процесс в машине, то мы станем лучше его понимать. Шахматы показали, что это не так: человечество научилось очень хорошо обучать компьютеры играть в шахматы, но не приблизилось ни на шаг к пониманию того, как шахматист делает свой интуитивный ход. И то же самое касается, видимо, всего остального, с чем мы имеем дело: компьютерное моделирование процесса не помогает узнать ничего об этом.
А филологам, может быть, нейросети всё-таки могут помочь, но для этого надо лучше понимать, что же филологов останавливает в их движении к мировому господству. Вот если мы это поймём лучше, то, возможно, получится обратить все минусы естественного интеллекта в плюсы.
Материал подготовлен в рамках спецпроекта «Писатели vs Нейросети»
Авторы: Руслан Родионов, Валерия Мелкозерова, Женя Колпащикова, Дарья Балуева
Редактор: Марина Панкова
Иллюстратор: Надежда Луценко
Кто работает с цифровым бессмертием и почему эти проекты прекращают работу
О создании цифровых копий человека говорят давно — это популярный сюжет фантастических произведений: например, оцифровке человека посвящена серия «Чёрного зеркала». В 2018 году появилось приложение Replika. В 2016 году его создательница Евгения Куйда вместе с командой программистов запустила чат-бота Roman, имитирующего личность своего близкого друга Романа Мазуренко, который погиб в автокатастрофе. Алгоритм составили на основе данных из постов, сообщений и текстов Мазуренко. Проект Replika компании Luca, сооснователем которой является Евгения, продолжает идею: это виртуальный собеседник, способный поддержать разговор и помочь справиться с трудными периодами в жизни.
В 2016 году был основан стартап Soul Machines, который создаёт цифровых андроидов и предлагает компаниям инструменты для создания собственных аватаров. Подобными технологиями занимаются и другие разработчики — ObEN, Sony, SberDevices. Осенью 2020 года в России начал работу стартап VIRperson — проект, который создаёт цифровые копии исторических личностей.

Главная страница сайта VIRperson
Руководитель и основатель VIRperson Роман Душкин занимается темой искусственного интеллекта более 20 лет, а четыре года назад он основал Агентство искусственного интеллекта. По его словам, многие стартапы занимаются оцифровкой личной памяти человека, но спустя время все работы как будто прекращаются и эти проекты начинают заниматься другим. К примеру, Luka стала делать бота-психолога.
Архитектуры нейронных сетей
На момент написания известно около 30 разновидностей нейронных сетей. Они имеют свои особенности и предназначены для решения различных задач.
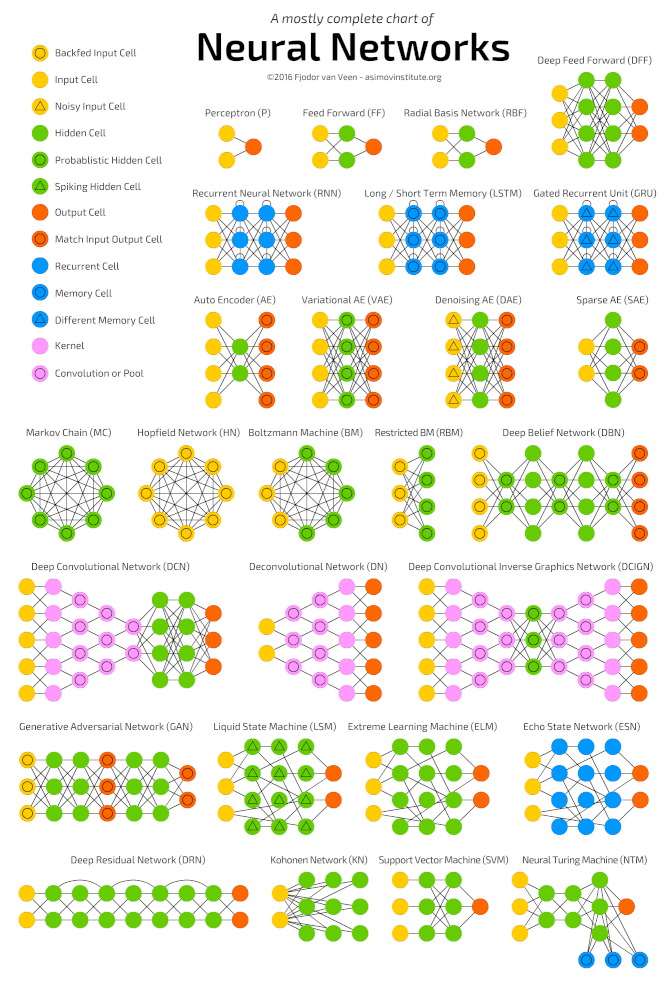
Типы нейронных сетей. Данные: The Asimov Institute.
Нейросети с прямой связью (FNN) используют в задачах распознавания и прогнозирования. Также их часто комбинируют с другими моделями для получения новых алгоритмов.
Такие сети работают в одном направлении — они передают информацию от входа к выходу.

Архитектура нейросети с прямой связью.
В FNN все нейроны собираются по слоям, которые состоят из входных, скрытых или выходных клеток. В пределах одного слоя нейроны не связаны между собой, но соседние слои — полностью связаны.
Сверточные нейросети (CNN) обычно применяют в связанных с компьютерным зрением задачах.
Начальные слои такой модели специализируются на извлечении различных характеристик из изображения, которые затем передаются в обычную нейронную сеть для классификации объектов на рисунке.
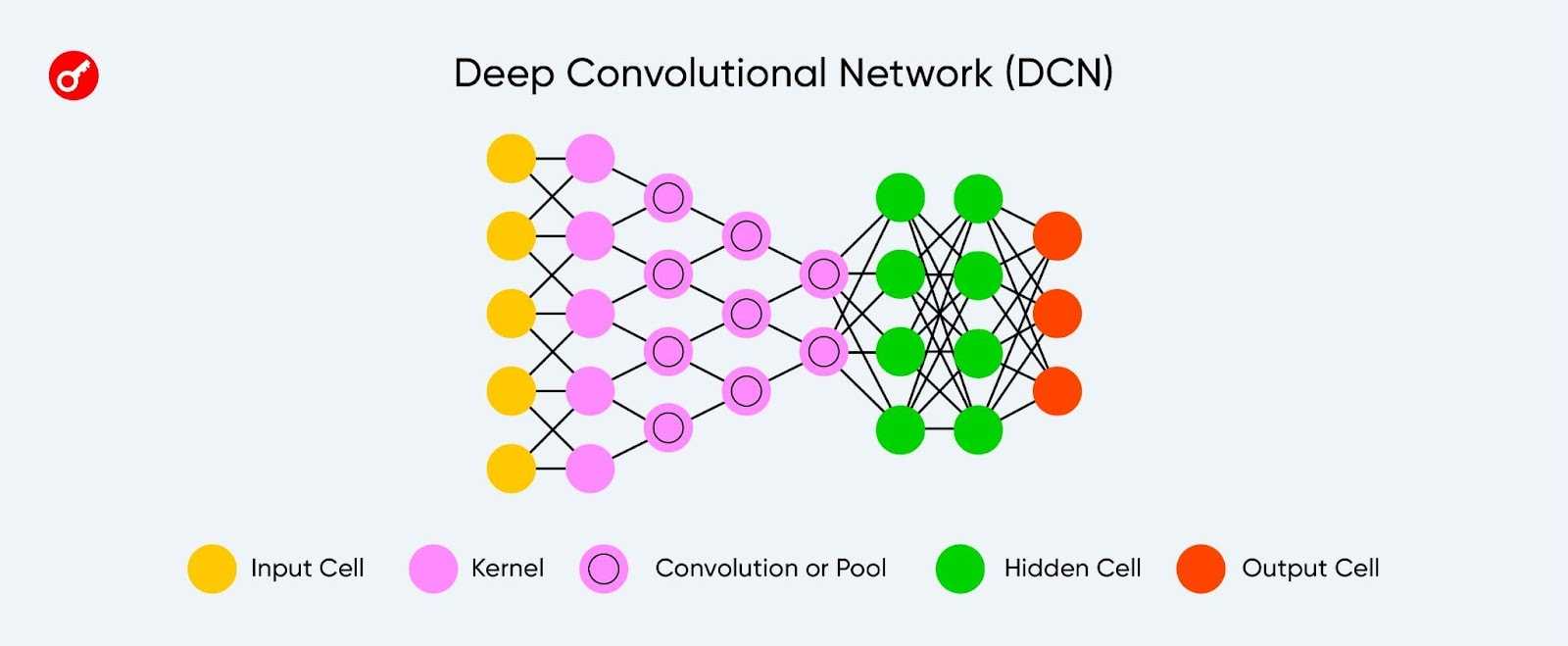
Архитектура глубокой сверточной нейронной сети.
CNN анализируют не все данные сразу, а проходятся по ним фильтром с заданным размером.
Например, при обработке изображения 200×200 пикселей CNN считывает квадрат размером 20×20 пикселей, сдвигается на один пиксель и считывает новый квадрат. Затем входные данные передаются через сверточные слои, в которых не все узлы соединены между собой.
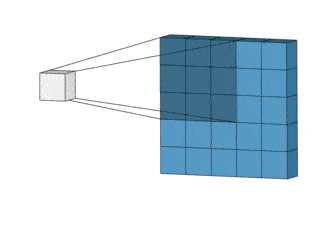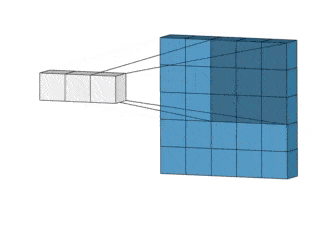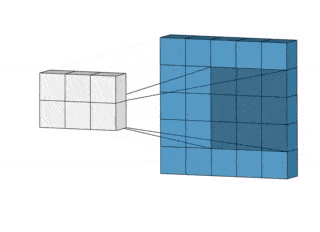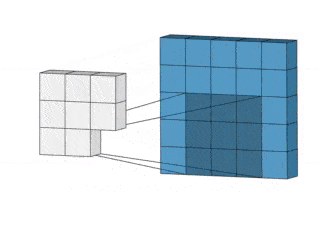
Двумерная свертка.
Рекуррентные нейронные сети (RNN) используют для обработки естественного языка.
Такие модели получают информацию не только от предыдущих слоев, но и от своей рекуррентной связи. То есть, нейросеть обучается запоминать также последовательность поступающих данных.
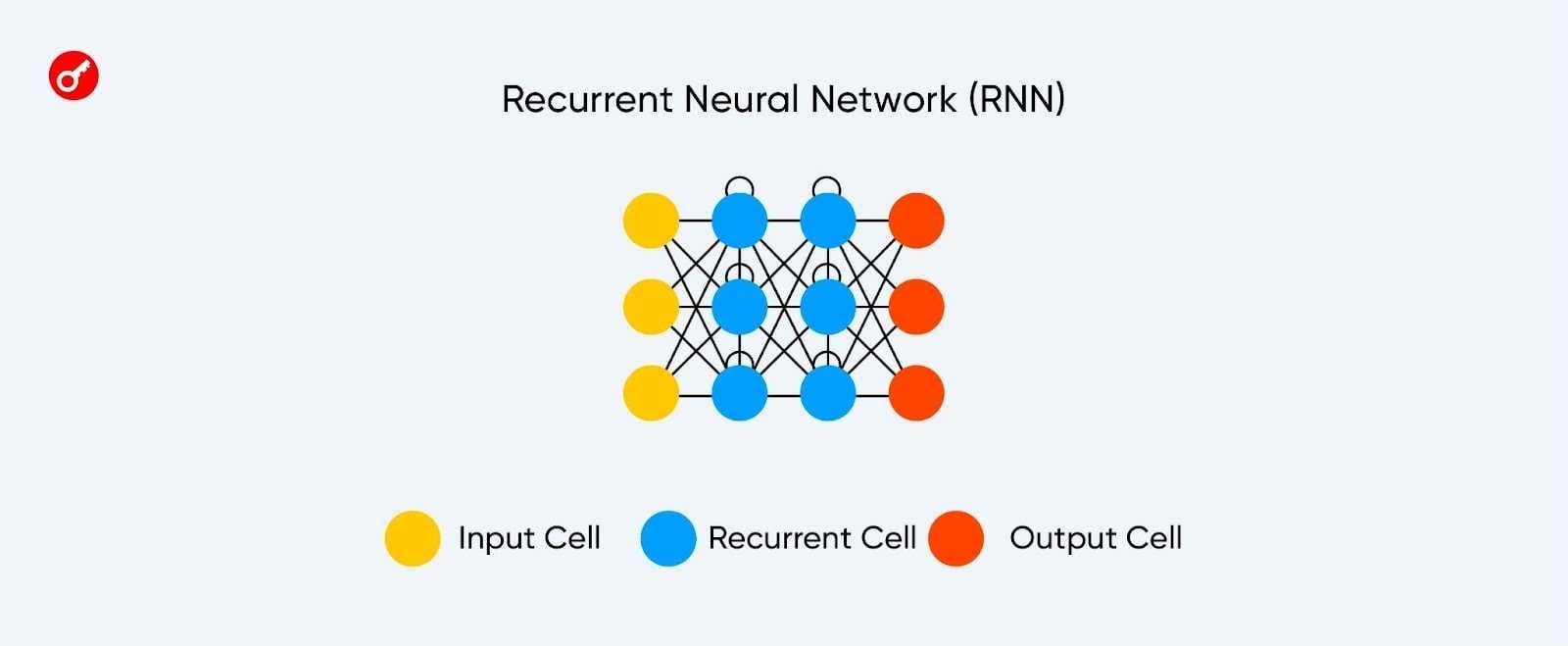
Архитектура рекуррентной нейронной сети.
Сложность RNN заключается в так называемой проблеме исчезающего градиента: сеть быстро теряет информацию с течением времени. Это влияет только на веса, а не на состояние нейронов, однако информация накапливается именно в них.








Сеть с долгой краткосрочной памятью (LSTM) решает проблему потери сведений в рекуррентных моделях.
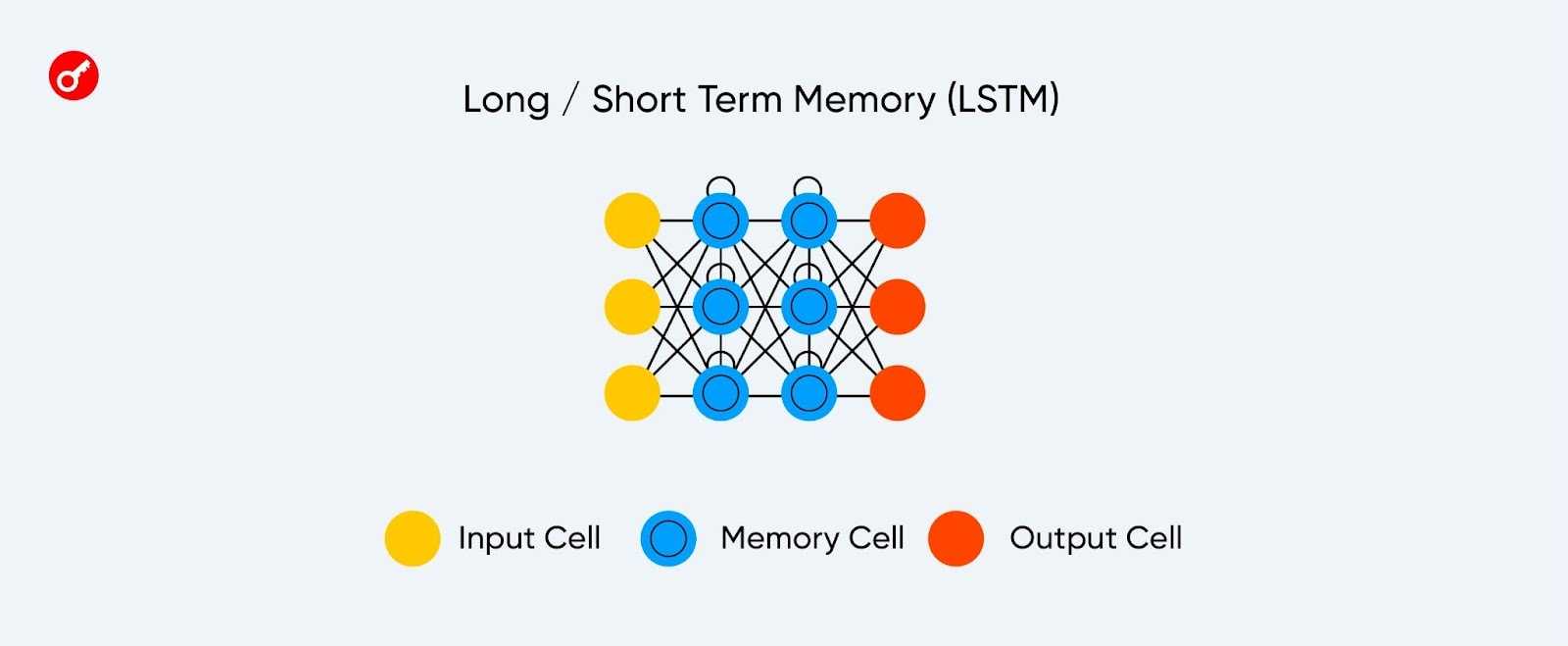
Архитектура сети с долгой краткосрочной памятью.
В LSTM каждый нейрон имеет клетку памяти и три фильтра: входной, выходной и забывающий. Их цель — защитить информацию.
Входной фильтр определяет, сколько сведений из предыдущего слоя будет храниться в клетке, а выходной — сколько их получат следующие слои.
Забывающий фильтр контролирует меру сохранения значения в памяти. Например, при переходе на новую главу книги он решает, какие символы стоит забыть из предыдущей.
Сети с долгой краткосрочной памятью способны создавать сложные структуры, но требуют большого количества ресурсов.
Генеративно-состязательные нейросети (GAN) применяют для создания дипфейков, аудио- или видеоконтента. Также на их основе разрабатывают приложения для стилизации фото.
GAN состоит из двух моделей: генератора, который создает контент, и дискриминатора, оценивающего его.

Архитектура генеративно-состязательной нейросети.
Сеть-дискриминатор получает обучающие или созданные генератором данные. Степень угадывания дискриминатором источника информации в дальнейшем участвует в формировании ошибки.
Таким образом, возникает состязание между генератором и дискриминатором: первый учится обманывать второго, а второй — раскрывать обман.