

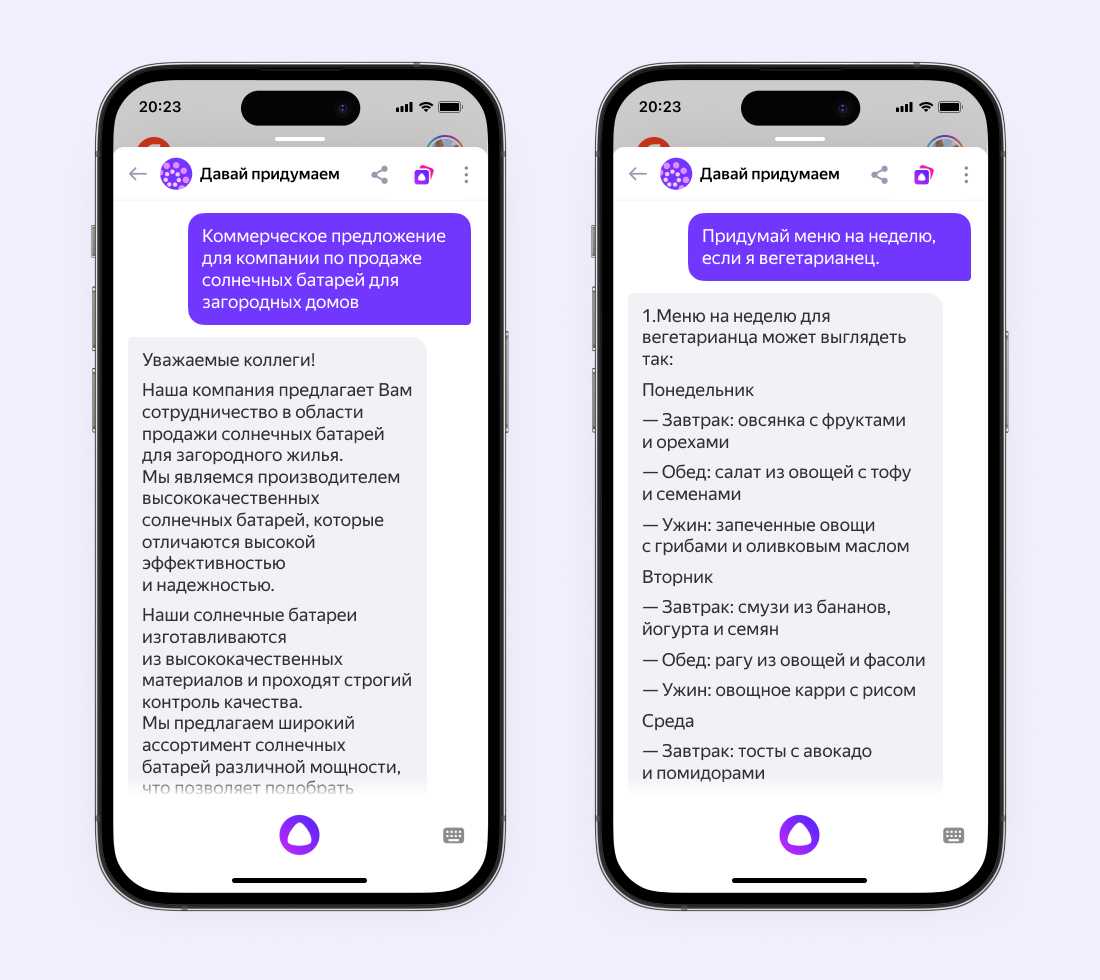
Введение в статистические языковые модели
Давайте глубже погрузимся в концепцию статистических языковых моделей. Языковая модель изучает вероятность появления слова на основе примеров текста. Более простые модели могут рассматривать контекст короткой последовательности слов, тогда как более крупные модели могут работать на уровне предложений или абзацев. Чаще всего языковые модели работают на уровне слов.
N-gram Language Models
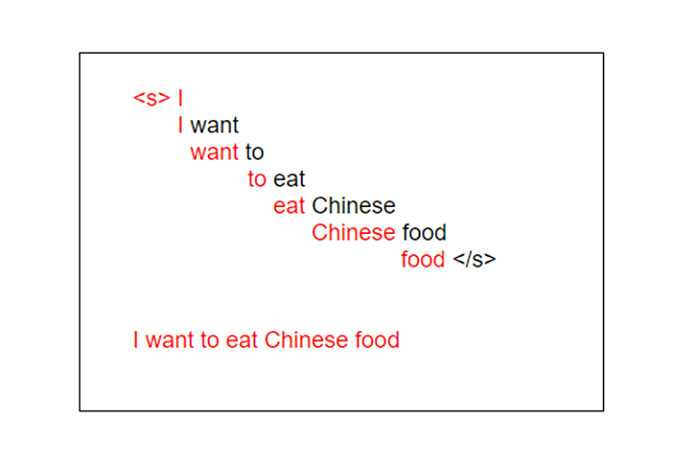
Модель n-грамм — это вероятностная языковая модель, которая может предсказывать следующий элемент в последовательности, используя (n — 1) -порядковую модель Маркова. Давайте лучше поймем это на примере. Рассмотрим следующее предложение:
«Я люблю читать блоги об образовании, чтобы изучать новые концепции»
1-грамм (или униграмма) — это последовательность из одного слова. Для приведенного выше предложения униграммы будут просто: «Я», «люблю», «чтение», «блоги», «в», «поучительно», «и», «учиться», «новое», «концепции»..
2 грамма (или биграмма) — это последовательность слов, состоящая из двух слов, например «я люблю», «люблю читать», «по вопросам образования» или «новые концепции».
И, наконец, 3-грамма (или триграмма) — это последовательность слов из трех слов, например «Я люблю читать», «Блоги по образовательным вопросам» или «изучайте новые концепции».
Модель языка N-граммов предсказывает вероятность данной N-граммы в любой последовательности слов на языке. Если у нас есть хорошая модель N-грамма, мы можем предсказатьр (ш | ч)п ( ш ∣ ч ), или вероятность увидеть слово w с учетом истории предыдущих слов h, где история содержит n-1 слово.
Пример: «Я люблю читать ___». Здесь мы хотим предсказать, какое слово заполнит черту, на основе вероятностей предыдущих слов.
Мы должны оценить эту вероятность, чтобы построить модель N-грамм. Мы вычисляем эту вероятность в два этапа:
- Примените цепное правило вероятности
- Затем мы применяем очень сильное упрощение, позволяющее легко вычислить p (w1… ws).
Цепное правило вероятности:
Определение: что такое цепное правило? Он говорит нам, как вычислить совместную вероятность последовательности, используя условную вероятность слова с учетом предыдущих слов.
Здесь у нас нет доступа к этим условным вероятностям со сложными условиями до n-1 слов. Итак, как мы будем действовать? Здесь мы вводим упрощающее предположение. Мы можем предположить для всех условий, что:
Здесь мы приближаем историю (контекст) слова wk, глядя только на последнее слово контекста. Это предположение называется предположением Маркова. Это пример модели биграммы. Эту же концепцию можно расширить, например, для модели триграммы формула будет выглядеть следующим образом:
У этих моделей есть основная проблема: они дают нулевую вероятность, если видно неизвестное слово, поэтому используется концепция сглаживания. При сглаживании мы присваиваем некоторую вероятность невидимым словам. Существуют различные типы методов сглаживания, такие как сглаживание Лапласа, хорошее сглаживание Тьюринга и сглаживание Кнезернея.
Введение в нейронные языковые модели
Модели нейронного языка имеют некоторые преимущества перед вероятностными моделями. Например, им не нужно сглаживание, они могут обрабатывать гораздо более длинные истории и могут делать обобщения по контекстам похожих слов.
Для обучающей выборки заданного размера нейронная языковая модель имеет гораздо более высокую точность прогнозов, чем языковая модель n-грамм.
С другой стороны, это повышение производительности связано с издержками: языковые модели нейронных сетей обучаются значительно медленнее, чем традиционные языковые модели, и поэтому для многих задач языковая модель N-граммы по-прежнему является правильным инструментом.
В нейронных языковых моделях предшествующий контекст представлен вложениями предыдущих слов. Это позволяет моделям нейронного языка обобщать невидимые данные намного лучше, чем языковые модели N-грамм.
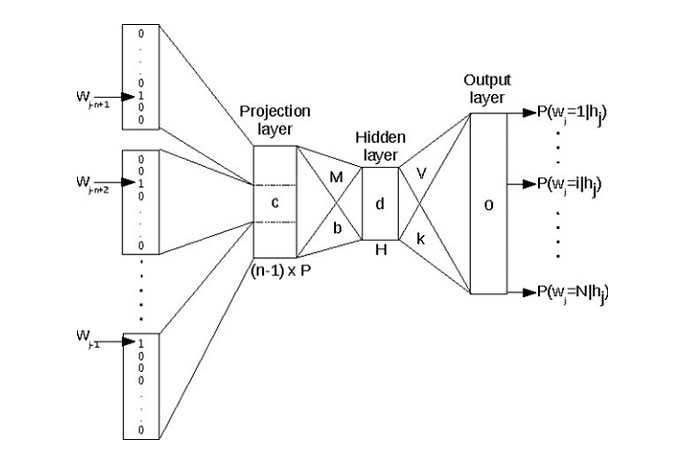
Вложения слов — это тип представления слов, который позволяет словам с похожим значением иметь аналогичное представление. По сути, встраивание слов — это класс методов, при которых отдельные слова представляются как векторы с действительными значениями в заранее определенном векторном пространстве.
Каждое слово сопоставляется с одним вектором, и значения вектора изучаются способом, напоминающим нейронную сеть. Каждое слово представлено вектором с действительными значениями, часто в десятках или сотнях измерений.
Примечание. Некоторые из техник внедрения слов — Word2Vec и GloVe.
Модели нейронного языка сначала были основаны на RNN и вложениях слов. Затем появилась концепция LSTM, GRU и кодировщика-декодера. Недавним достижением стало открытие трансформеров, которые коренным образом изменили сферу языкового моделирования.
Некоторые из самых известных языковых моделей, такие как BERT, ERNIE, GPT-2 и GPT-3, RoBERTa, основаны на Transformers.
Затем RNN складывались в стек и использовались двунаправленно, но они не могли улавливать долгосрочные зависимости. Для устранения этого недостатка были введены LSTM и ГРУ.
Трансформаторы образуют основные строительные блоки новых моделей нейронного языка. Представлена концепция трансферного обучения, которая стала большим прорывом. Модели были предварительно обучены с использованием больших наборов данных.
Например, BERT обучен на всей английской Википедии. Для обучения моделей использовалось обучение без учителя. GPT-2 обучен на наборе из 8 миллионов веб-страниц. Затем эти модели настраиваются для выполнения различных задач НЛП.
Типы языковых моделей
Есть две категории, к которым относятся языковые модели:
Статистические языковые модели: в этих моделях используются традиционные статистические методы, такие как N-граммы, скрытые марковские модели (HMM) и установленные лингвистические правила для изучения вероятностного распределения слов. Статистическое моделирование языка включает в себя разработку вероятностных моделей, которые могут предсказать следующее слово в последовательности, учитывая слова, которые ему предшествуют.
Модели нейронного языка: эти модели являются новыми игроками в мире НЛП и превзошли статистические языковые модели по своей эффективности. Они используют разные типы нейронных сетей для моделирования языка. Использование нейронных сетей при разработке языковых моделей стало настолько популярным. Что теперь это предпочтительный подход для решения сложных задач, таких как распознавание речи и машинный перевод.
Примечание. GPT-3 является примером модели нейронного языка. BERT от Google — еще одна популярная модель нейронного языка, используемая в алгоритме поисковой системы для предсказания следующего слова нашего поискового запроса.
आज का नया मुद्रा बाज़ार नेता
सर्वोत्तम मुद्रा बाज़ार खातों की हमारी दैनिक रैंकिंग में आज रिपब्लिक बैंक ऑफ़ शिकागो सबसे आगे है। इसकी 5.21% एपीवाई दर न्यूनतम जमा और 2,500 डॉलर की चालू शेष राशि के साथ उपलब्ध है। यह चार राज्यों: इलिनोइस, इंडियाना, मिशिगन और विस्कॉन्सिन के निवासियों को छोड़कर, अमेरिका में किसी के लिए भी ऑनलाइन खोलने के लिए उपलब्ध है।
यदि न्यूनतम शेष राशि या आपके निवास की स्थिति बाधा है, तो परेशान न हों, क्योंकि इस समय असाधारण दर अर्जित करने के लिए कई अन्य विकल्प मौजूद हैं। हमारी रैंकिंग देश में शीर्ष 15 दरों को सूचीबद्ध करती है, जिसमें तीन अन्य विकल्प भी शामिल हैं जो 5.00% या बेहतर भुगतान करते हैं।
यदि आपको अपने खाते से पेपर चेक लिखने के विकल्प की परवाह नहीं है, तो आपको सर्वोत्तम उच्च-उपज वाले बचत खातों पर भी विचार करना चाहिए । हालांकि वहां का रेट लीडर 5.20% एपीवाई का भुगतान कर रहा है — नए मनी मार्केट लीडर से एक आधार अंक कम — कम से कम 5.00% का भुगतान करने वाले विकल्पों की सूची उन खातों के लिए अधिक मजबूत है, जिससे आपको 5.00% एपीवाई या अधिक का भुगतान करने वाले 14 अन्य विकल्प मिलते हैं।
Building Products with Summarization AI
Text Summarization is used across a wide range of industries and applications.
Use cases include:
- Creating chapters for YouTube videos or educational online courses via video editing platforms.
- Summarizing and sharing key parts of corporate meetings to reduce the need for mass attendance.
- Automatically identifying key parts of calls and flagging sections for follow-up via revenue intelligence platforms.
- Summarizing large analytical documents to ease readability and understanding.
- Segmenting podcasts and automatically providing a Table of Contents for listeners.
Additional Resources:
- How to use AI to automatically summarize meeting transcripts
- 3 easy ways to add AI Summarization to Conversation Intelligence tools
- How to use Speech to Text AI for Ad Targeting & Brand Protection
- How to use Speech AI systems for podcast hosting, editing, and monetization
- Build standout call coaching features with AI Summarization
Конец первой части: GPT-2, дамы и господа
Итак, мы прошлись по тому, как работает GPT-2. Если вам любопытно узнать, что именно происходит внутри слоя внутреннего внимания, то следующая бонусная часть определенно для вас. Она была создана для того, чтобы предложить некоторые визуальные средства для описания механизма внутреннего внимания и облегчить дальнейший разбор моделей трансформера (таких как TransformerXL и XLNet).

Хотелось бы отметить некоторые упрощения, к которым пришлось прибегнуть в этой статье:
«Слова» и «токены» использовались как синонимы и в этой статье взаимозаменяемы; однако на самом деле GPT-2 использует парную байтовую кодировку (Byte Pair Encoding) для создания токенов своего словаря. Это означает, что обычно токенами являются части слова.
В нашем примере модель GPT-2 работает в режиме вывода/оценки (inference/evaluation mode). Вот почему она обрабатывает только одно слово за раз. Во время обучения модель будет обучаться на более длинных последовательностях текста и обрабатывать единовременно несколько токенов. Также на этапе обучения модель может обрабатывать батчи больших размеров (512), в отличие от батчей размером 1, которые используются в режиме оценки.
Автор был несколько волен в ротации/транспозиции векторов для лучшей организации пространства и картинок
Во время применения модели необходимо быть более точным.
В Трансформерах широко применяется техника нормализации слоев, и это достаточно важно. Мы отметили некоторые примеры ее использования в Transformer в картинках, а в этой статье в основном сосредоточимся на внутреннем внимании.
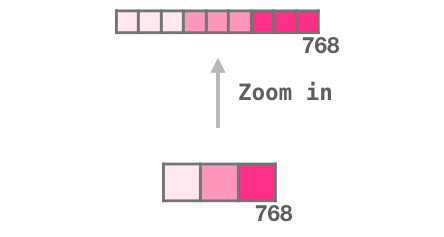
В некоторых случаях было необходимо изобразить больше квадратиков для представления вектора
Эти случаи были описаны как «zoom in», например:
Часть 2: визуализация внутреннего внимания
Ранее в статье мы показывали эту картинку для иллюстрации применения внутреннего внимания в слое, обрабатывающем слово «it»:

В этой части мы рассмотрим более детально то, как это происходит. При этом мы будем пытаться понять, что происходит с каждым конкретным словом, поэтому далее будет много иллюстраций отдельных векторов. И хотя в реальности применение внутреннего внимания происходит с помощью перемножения гигантского размера матриц, мы остановимся здесь на интуиции того, что происходит на уровне одного слова.
Экспресс-курс по нейрохирургии: заглядывая внутрь GPT-2
Давайте положим обученную GPT-2 модель на наш операционный стол и посмотрим, как она работает.
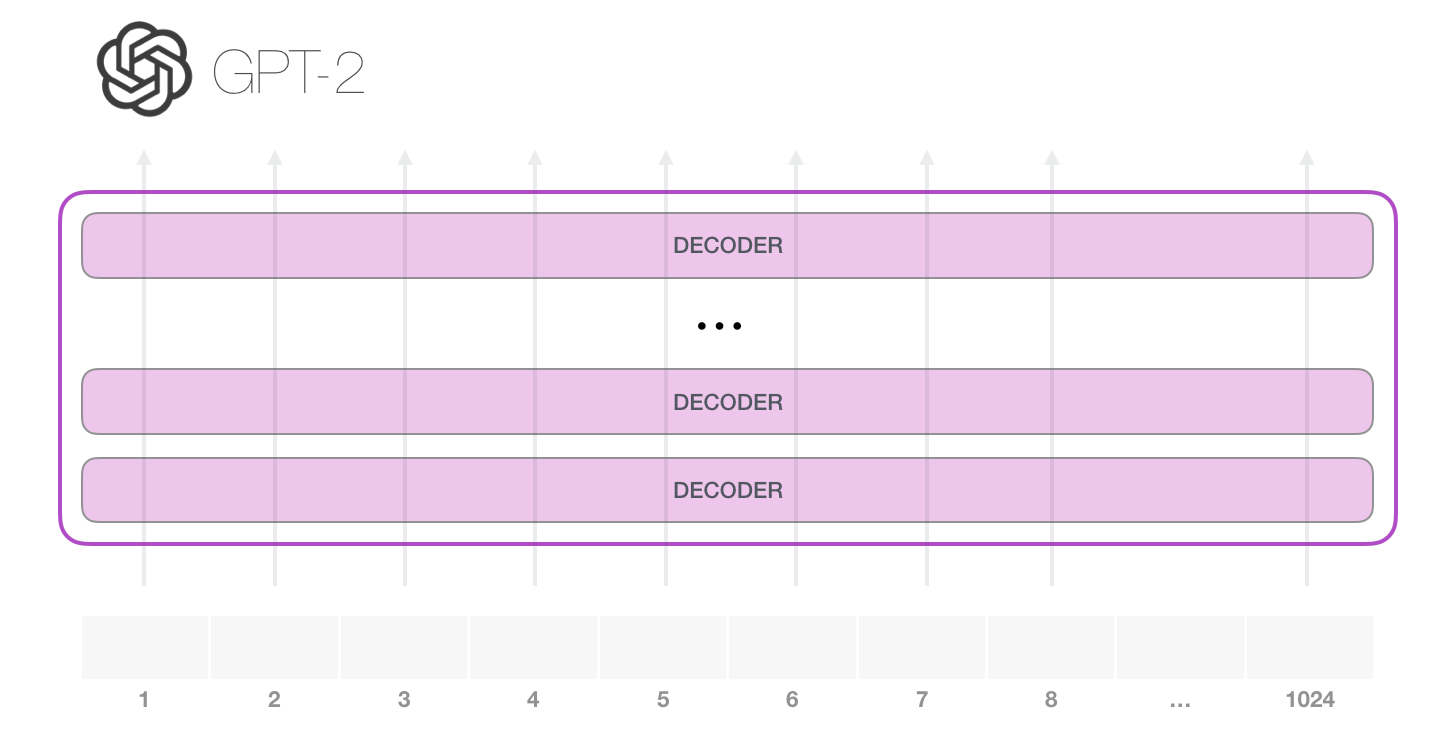
GPT-2 может обработать 1024 токена. Каждый токен проходит через все блоки декодера по своей собственной траектории.
Самый простой способ запустить обученную GPT-2 – пустить ее в свободное плавание (что технически называется генерацией безусловных выборок) или дать ей пример (подсказку), чтобы она могла говорить на определенную тему (т.е. генерация интерактивных условных выборок). В первом случае мы можем просто передать ей стартовый токен, и модель начнет генерировать слова (обученная модель использует в качестве стартового токена <|endoftext|>; обозначим его просто как <|s|>).
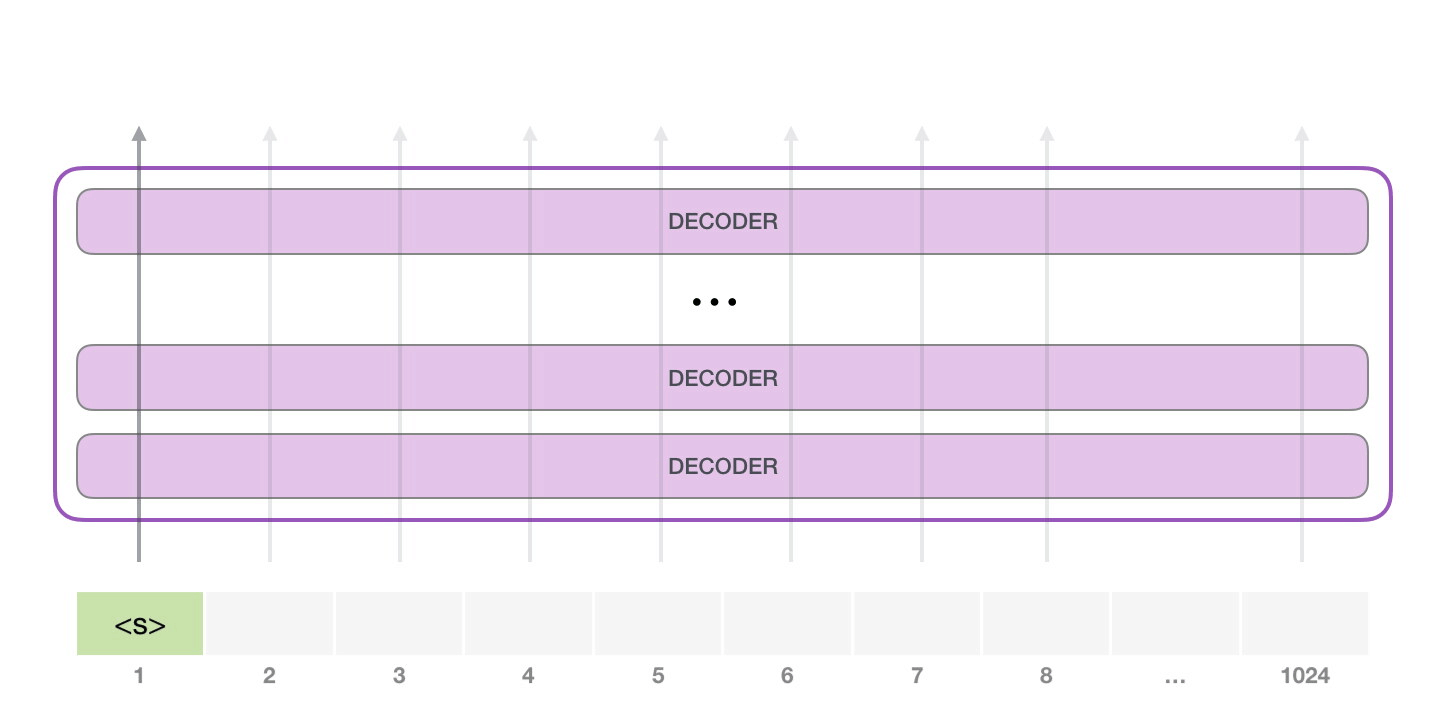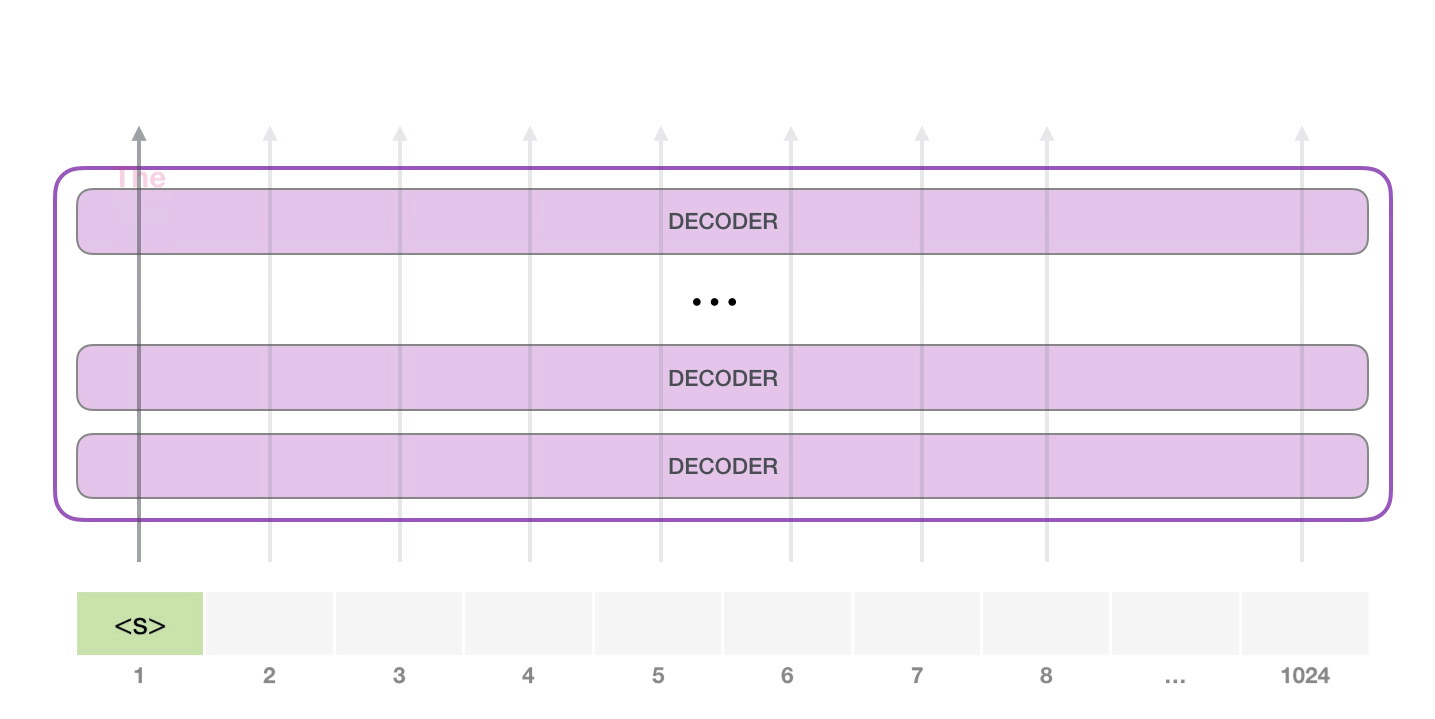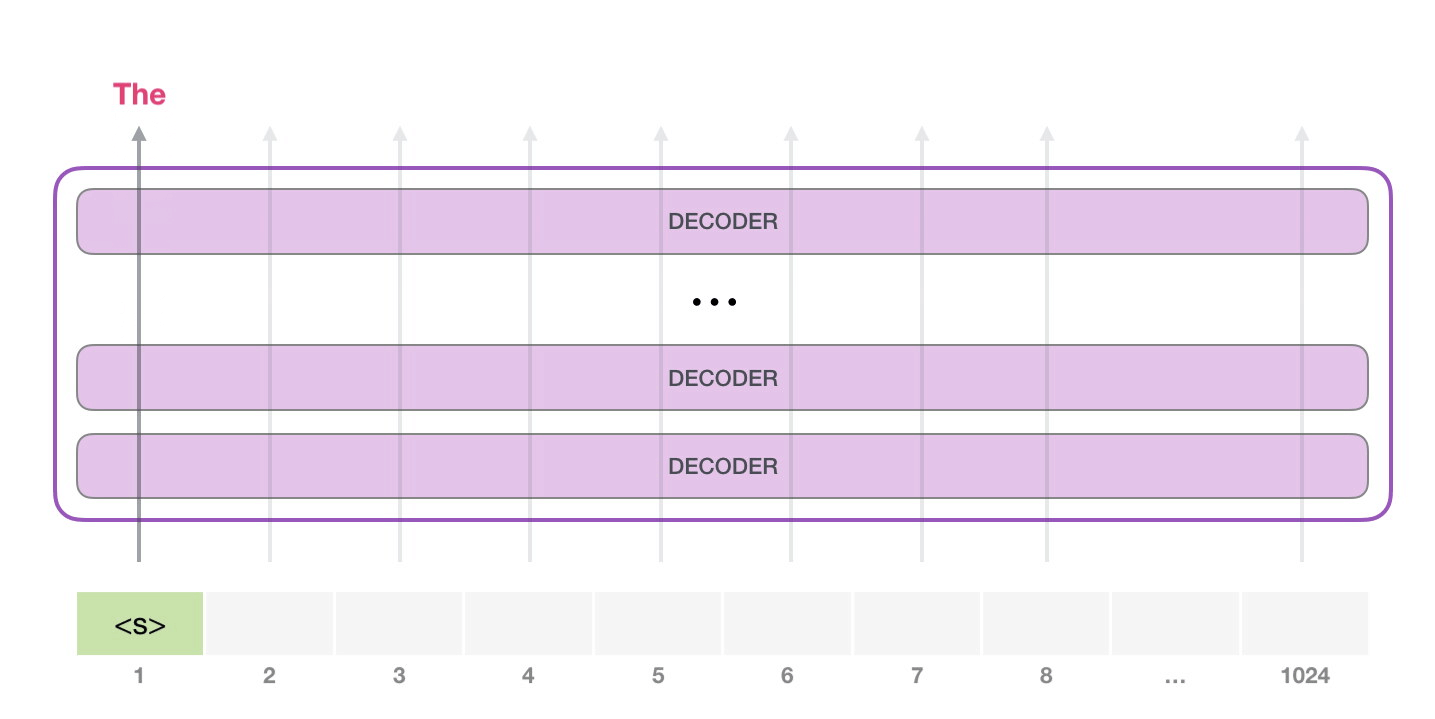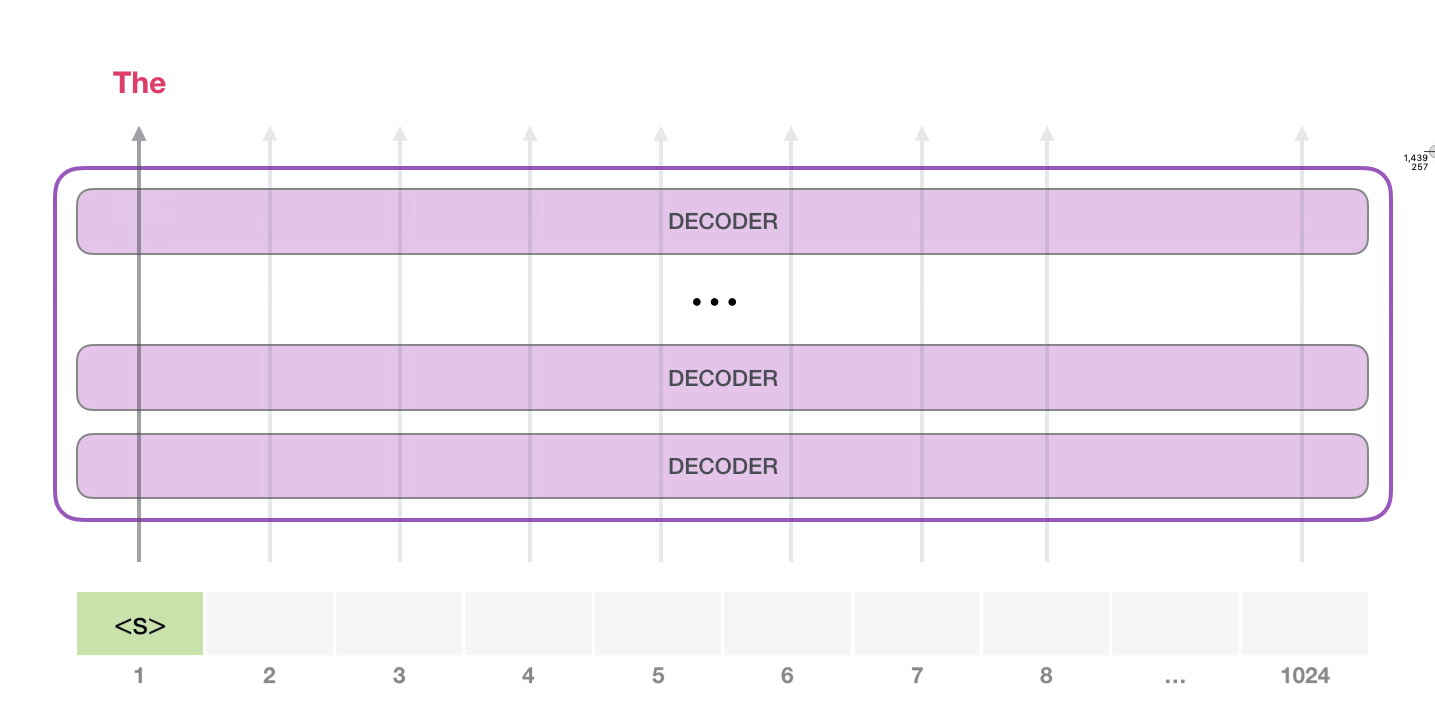
У модели есть только один входной токен, так что первая траектория окажется единственной активной. Токен успешно обрабатывается всеми слоями декодера и преобразуется в вектор, которому присваивается коэффициент (score) относительно словаря – всех слов, которые модель знает (50 тысяч слов у GPT-2). В нашем случае мы выбрали токен с наибольшей вероятностью – «the». Но есть шанс что-то перепутать – вы знаете, как бывает, когда вы пытаетесь нажать на предложенное слово на клавиатуре, и оно застревает в повторяющемся цикле, единственный выход из которого – нажать на второе или третье предложенное слово. То же может произойти и здесь. GPT-2 имеет параметр top-k, который мы можем использовать для того, чтобы модель рассматривала некоторую выборку слов, а не только топ слово (последнее, по сути, является случаем top-k = 1).
На следующем этапе мы добавляем наш выход во входную последовательность и модель предсказывает следующее слово:
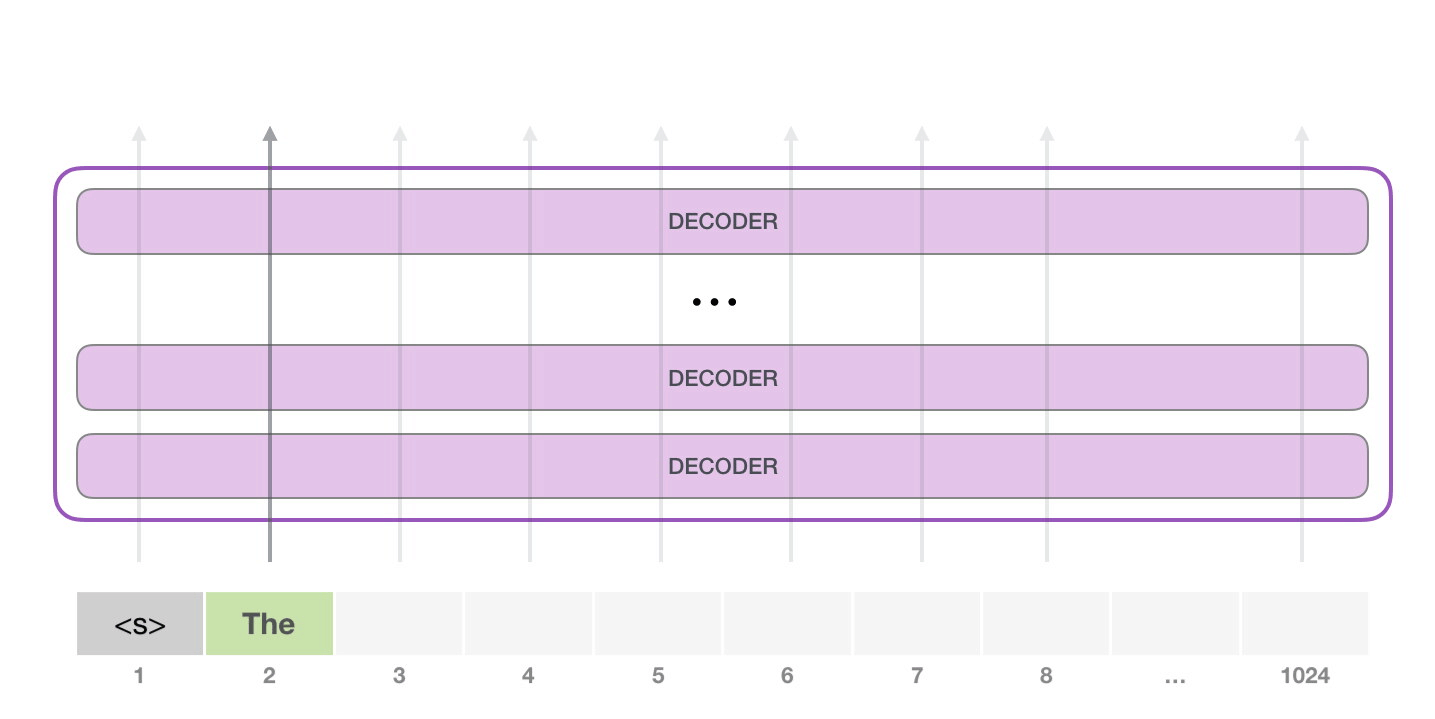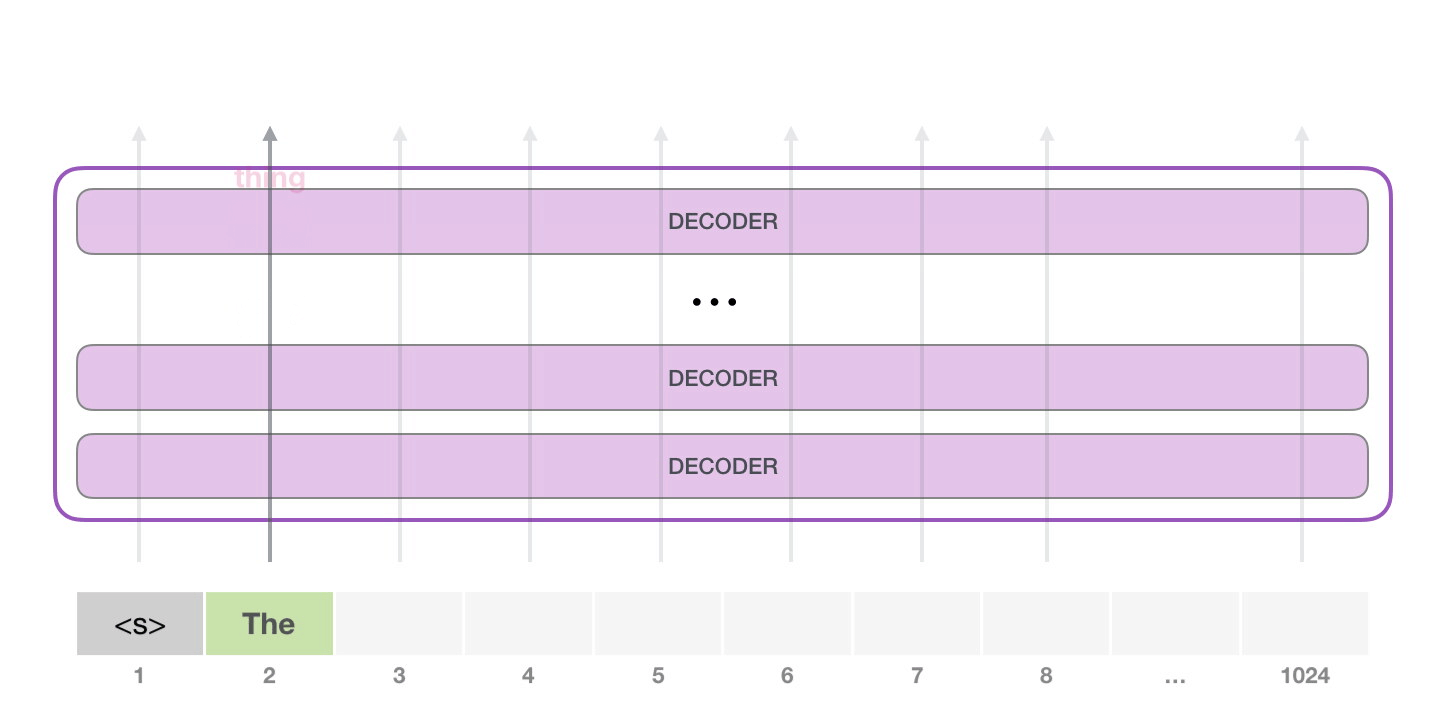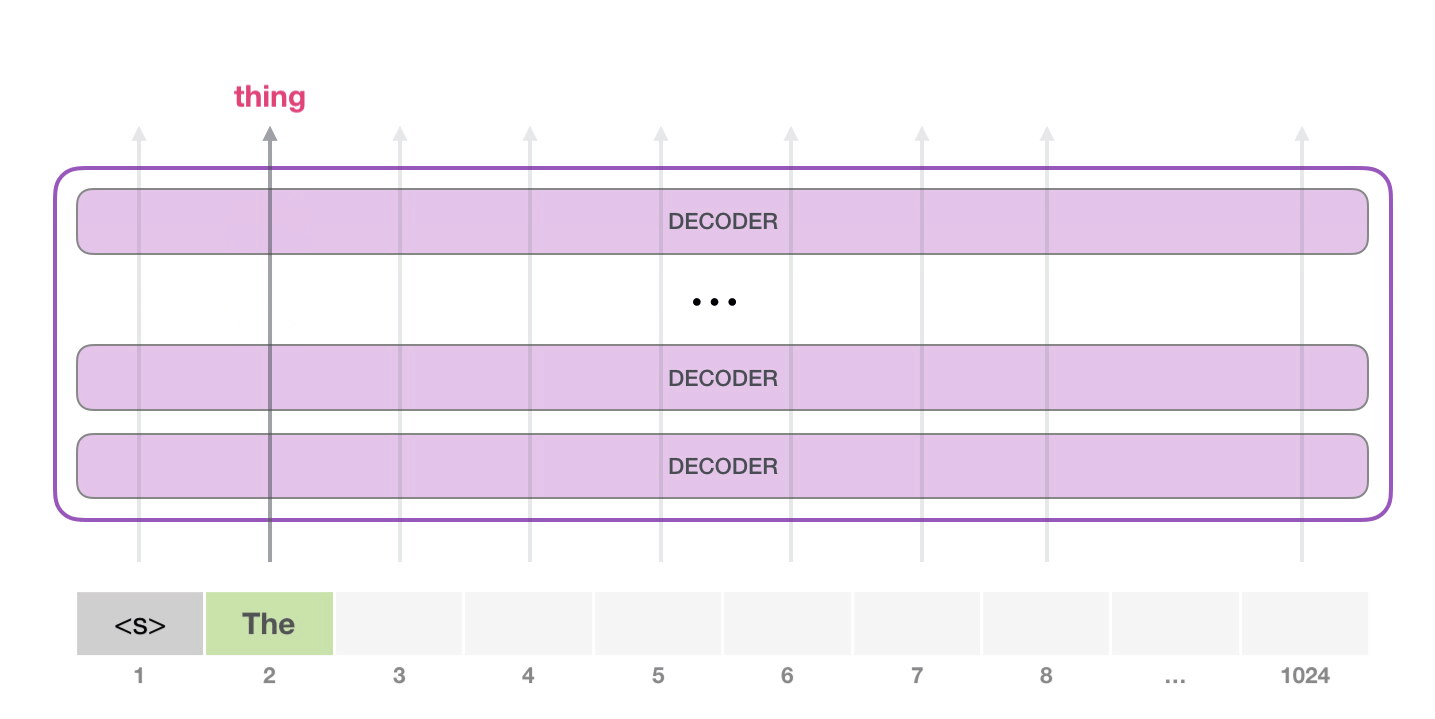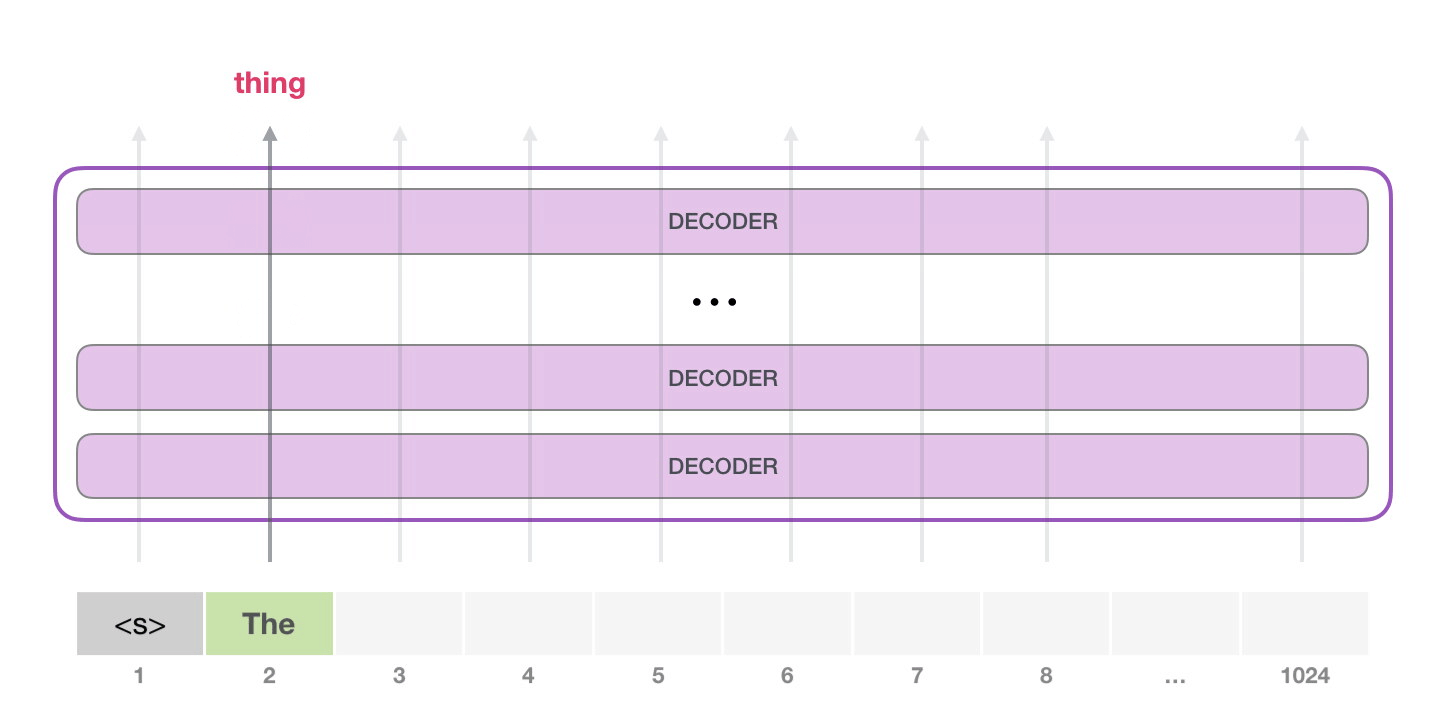
Обратите внимание, что в этой итерации активна лишь вторая траектория. Каждый слой GPT-2 сохраняет свою собственную интерпретацию первого токена и будет использовать ее в обработке второго (более подробно мы расскажем чуть ниже в разделе о внутреннем внимании)
GPT-2 не переинтерпретирует первый токен после появления второго.
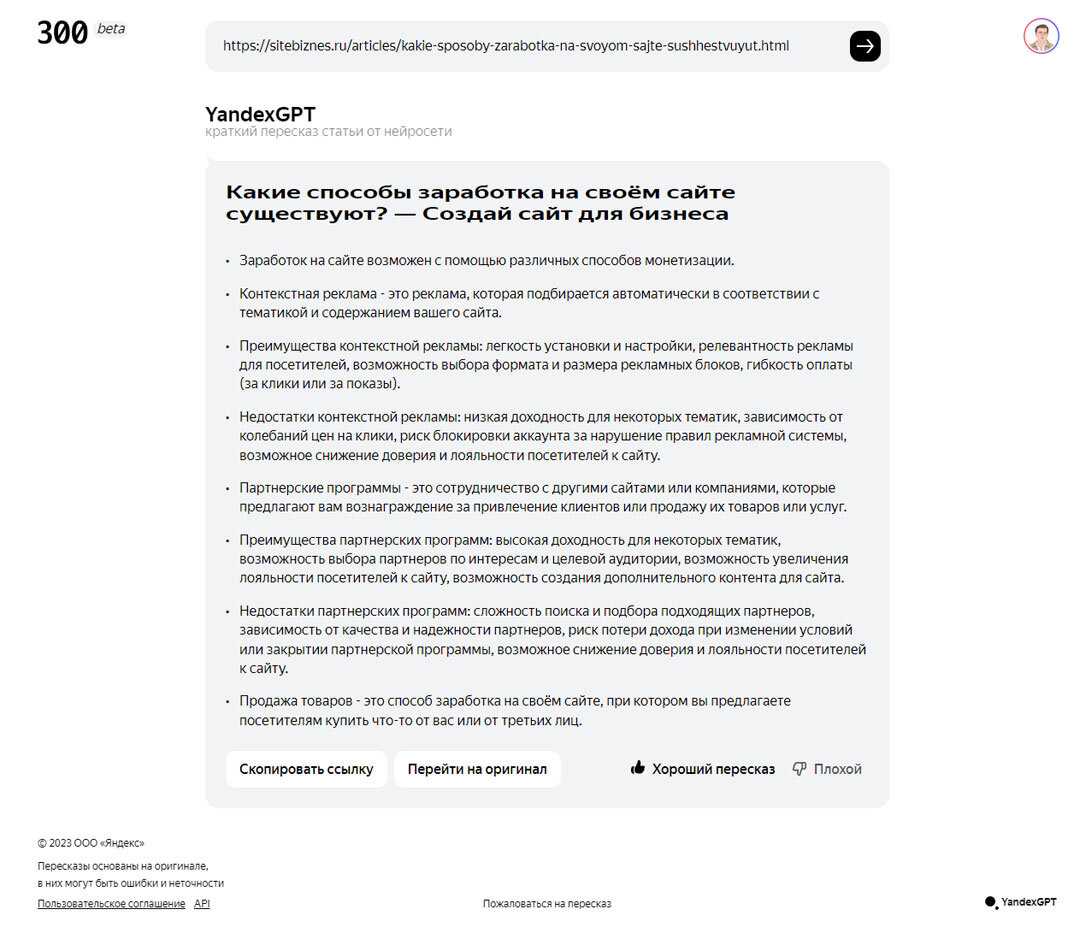
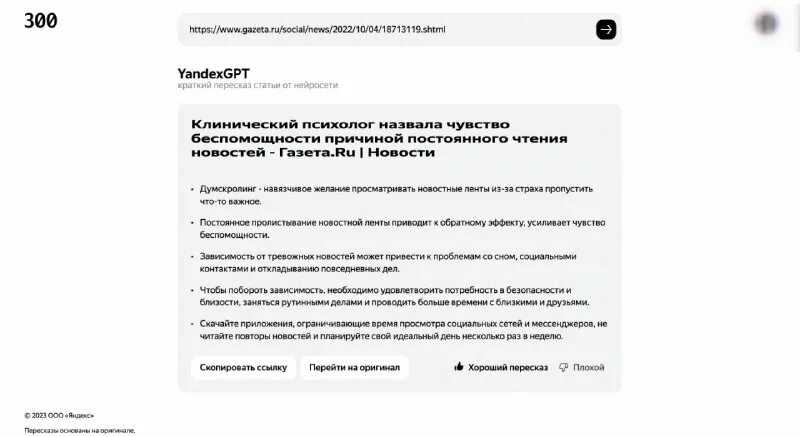
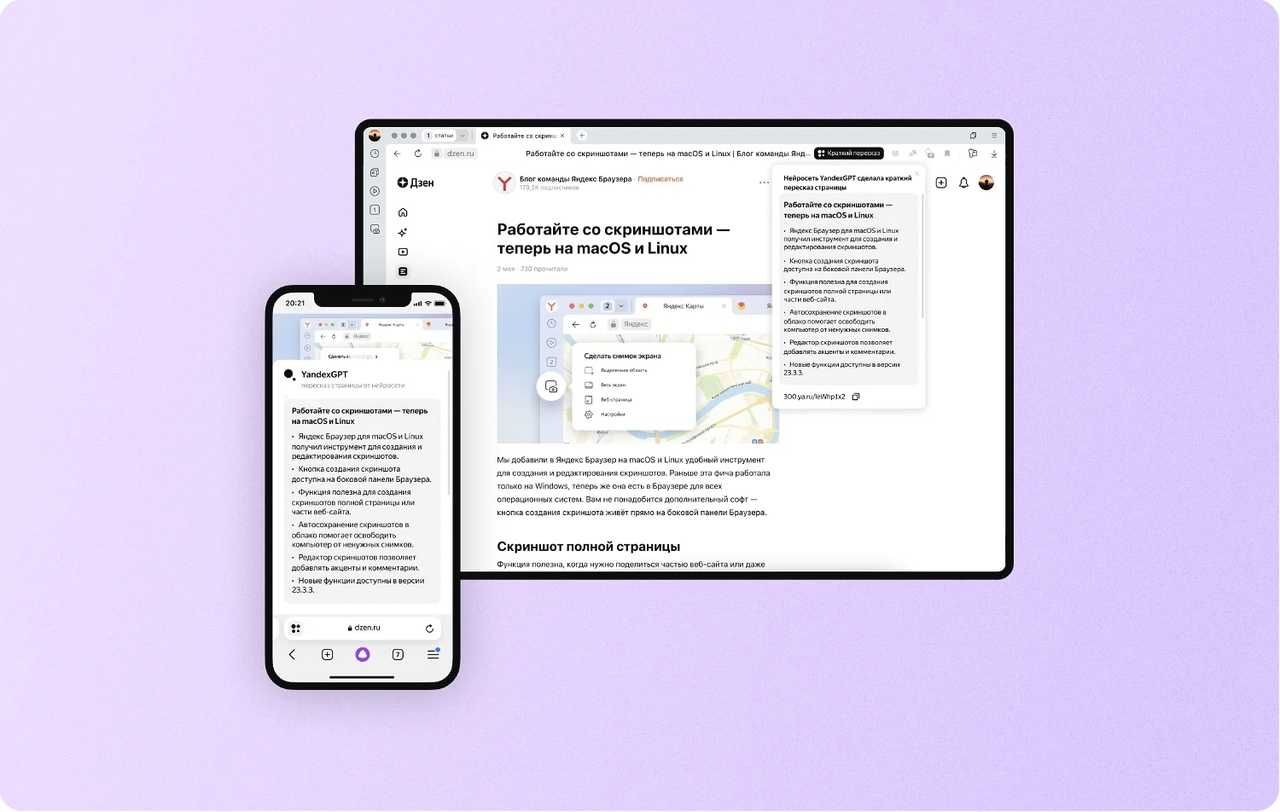
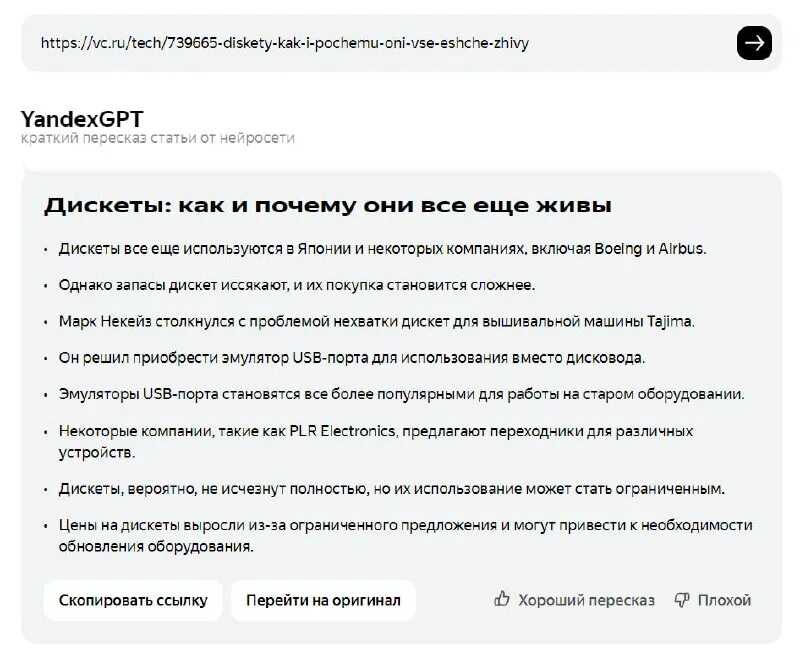
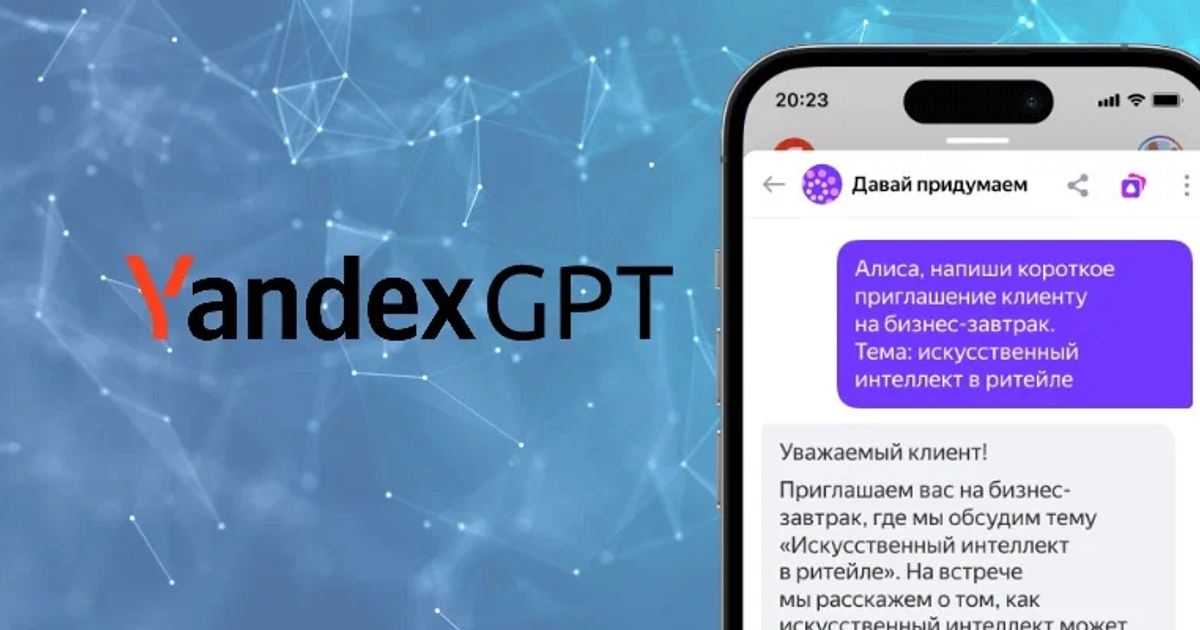
Что такое YandexGPT
YandexGPT представляет собой находящуюся на этапе тестирования нейросеть, разработанную российской компанией Яндекс.

Основная специализация этой модели искусственного интеллекта – генерация текстов, основанная на технологии обработки естественного языка.
Нейросеть поддерживает работу с различными языками: русский, английский, немецкий и др.
Функционал нейросети позволяет ей выполнять целый ряд различных задач:
- Генерацию текстов различного формата по пользовательскому запросу на заданную тему.
- Перевод статей с одного языка на другой.
- Создание рекламных материалов текстового формата.
- Ответы на вопросы на понятном для читателя и естественном языке.
- Анализ текстового материала с целью выявления ключевых слов и фраз.
- Написание программного кода.
- Заполнение форм на автоматической основе.
На выполнении вышеперечисленных задач функционал искусственного интеллекта далеко не ограничивается. Компания на постоянной основе развивает и модернизирует данную нейросеть, стараясь сделать ее максимально полезной для пользователя.
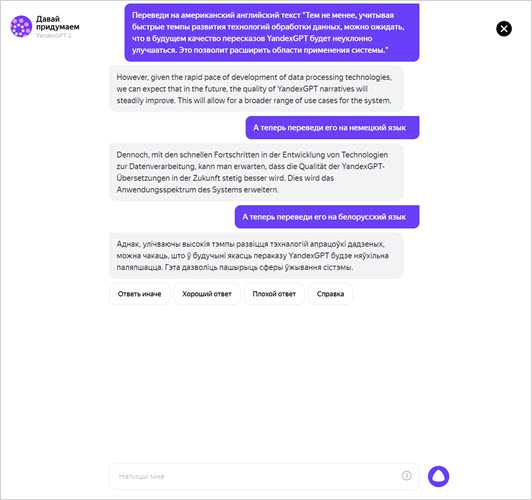
Именно по этой причине данный инструмент используется не только в отдельности, как ChatGPT, но и интегрируется в другие полезные сервисы.
К примеру, в мае 2023 года Яндекс встроил свою нейросеть в помощника «Алису», научив ее предлагать интересные идеи и писать тексты на базе этой модели ИИ.
Также данная нейросеть используется в таких сервисах от Яндекс как «Практикум», «Лавка» и «Маркет».
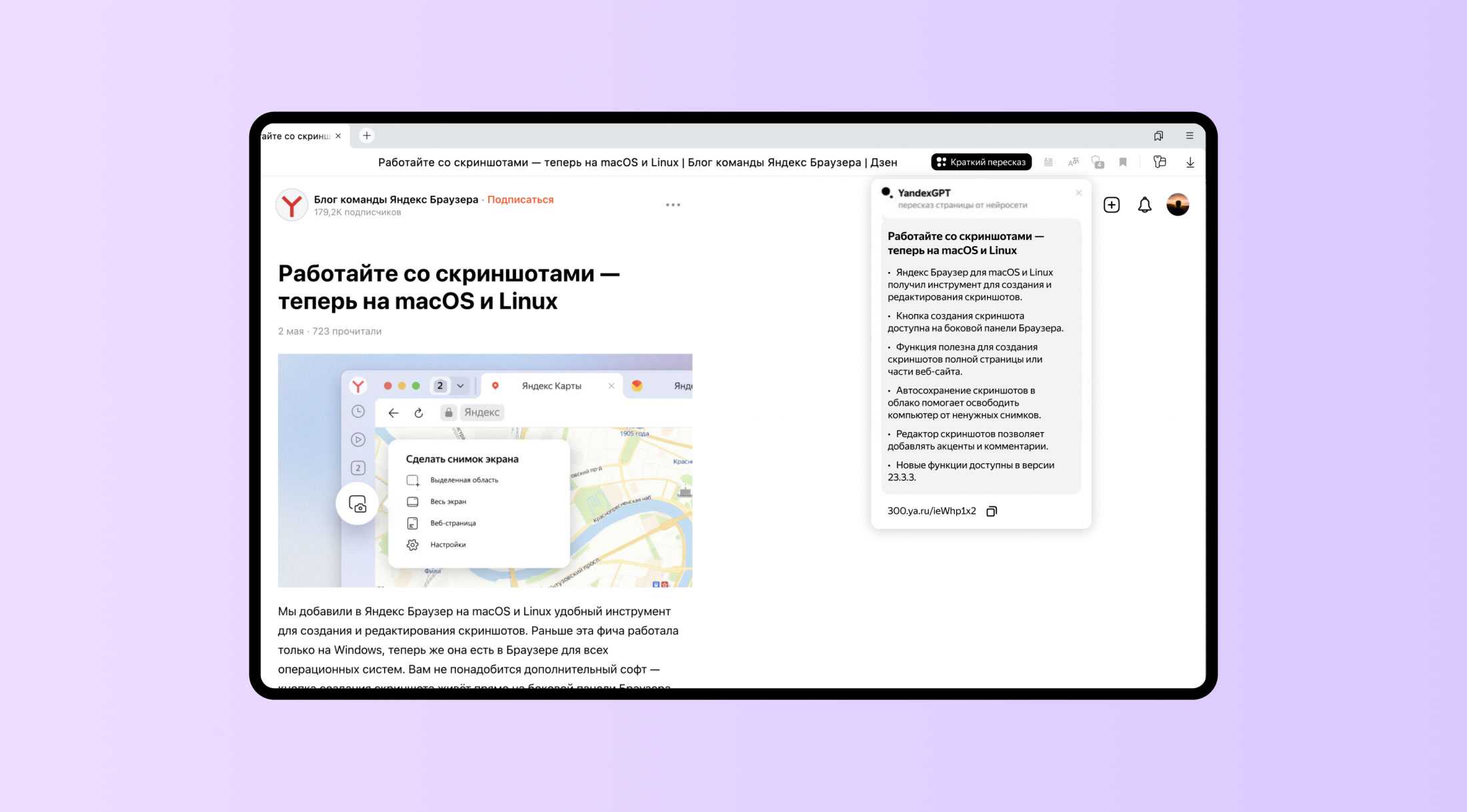
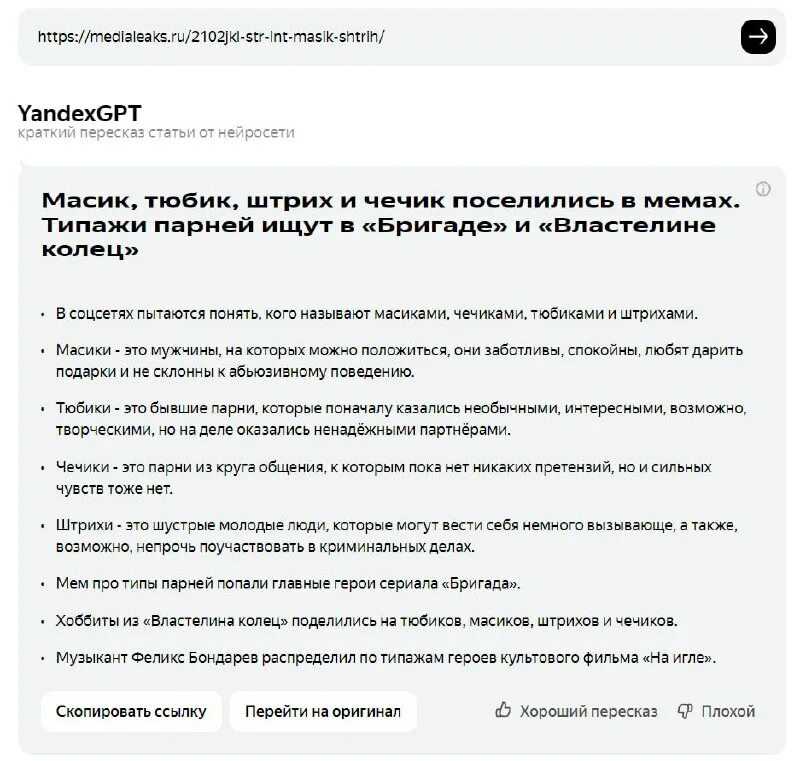
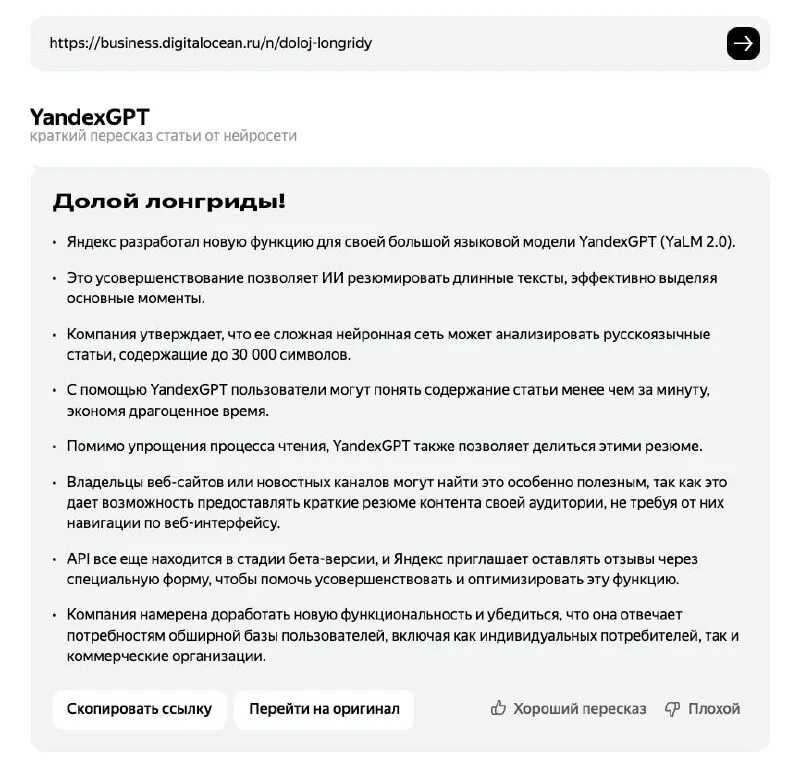
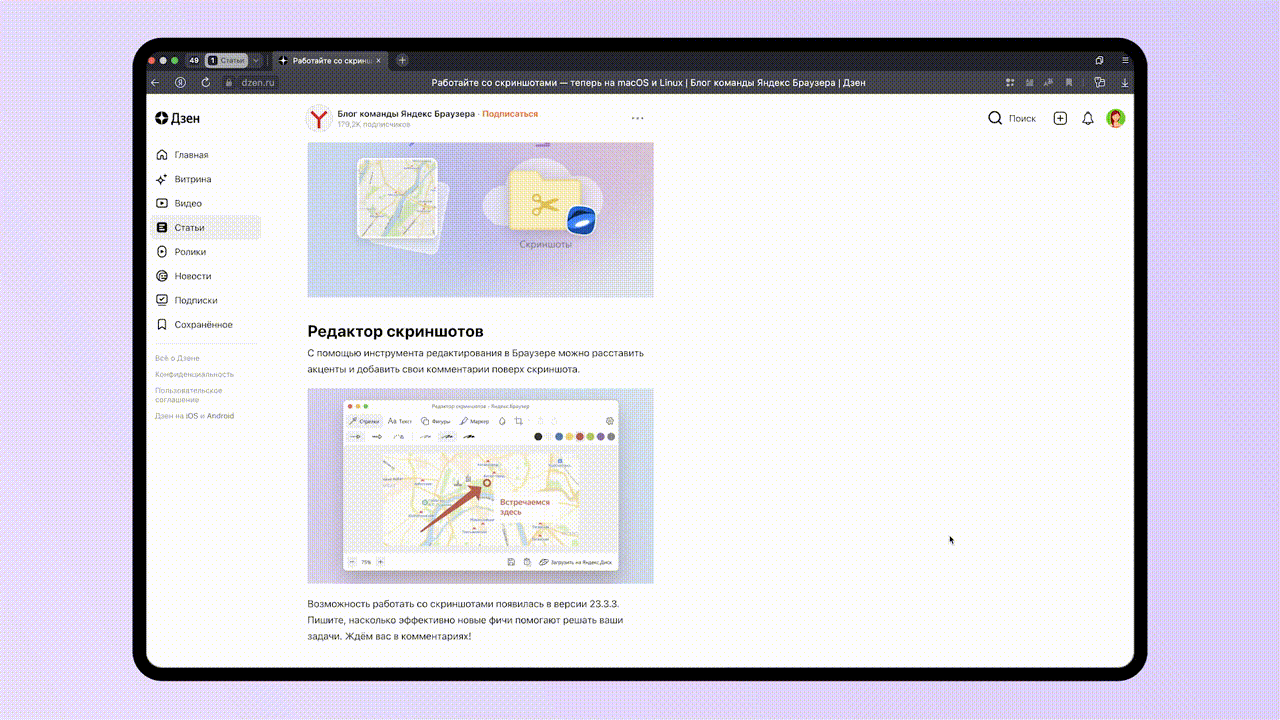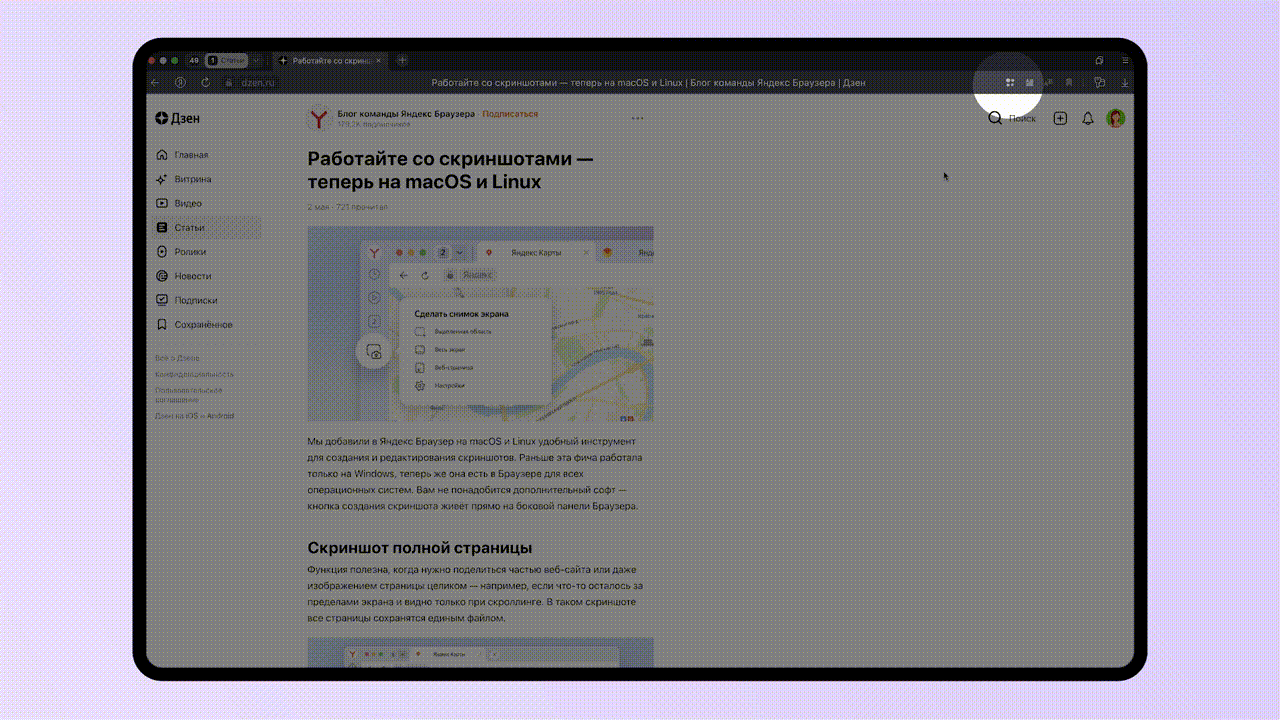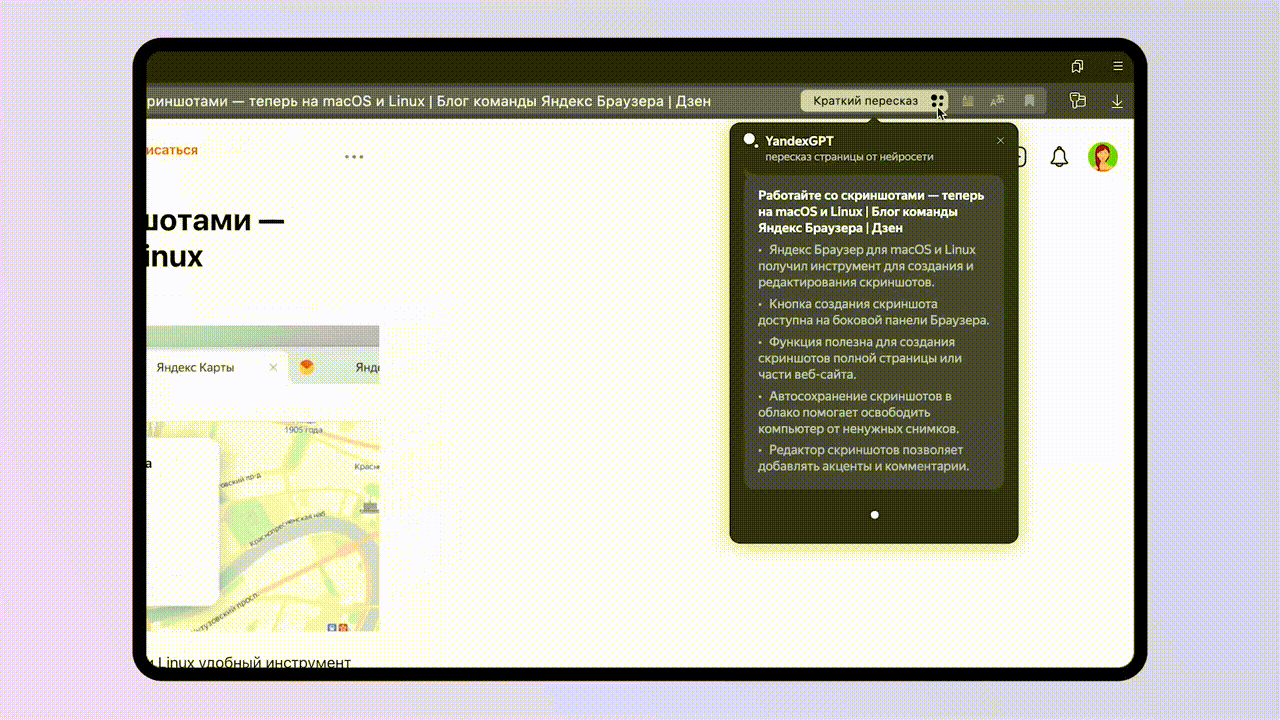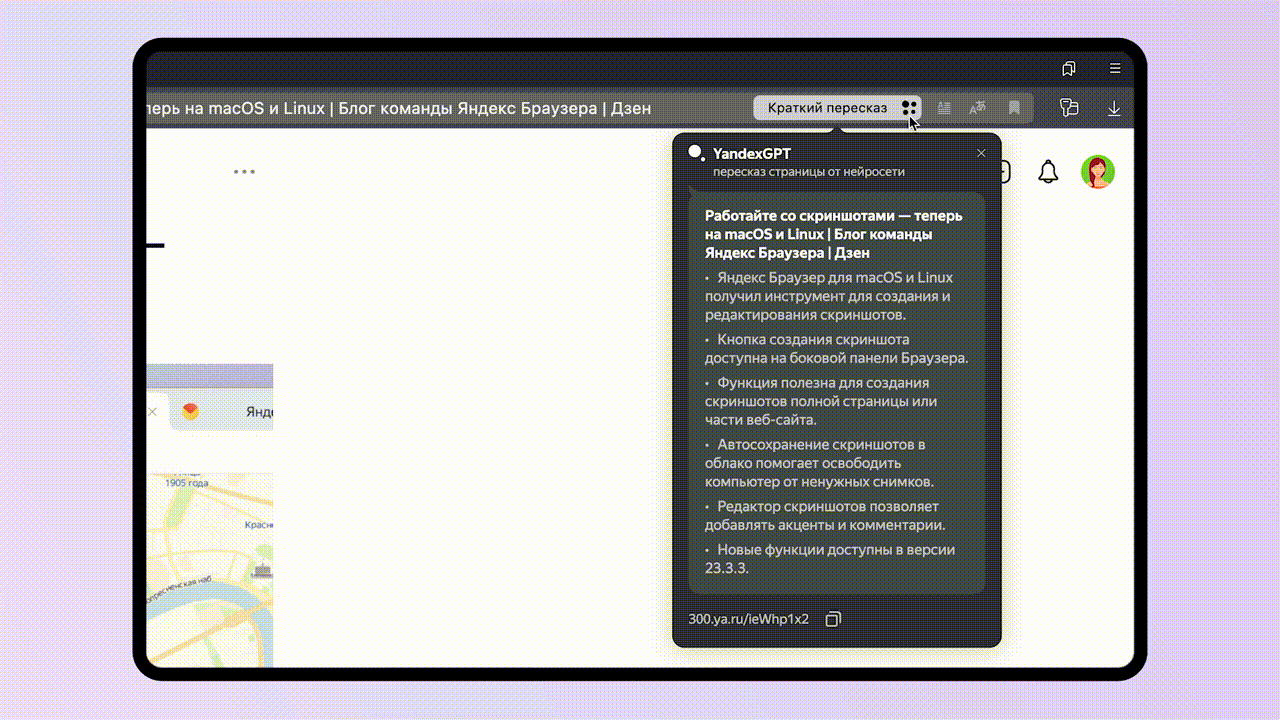
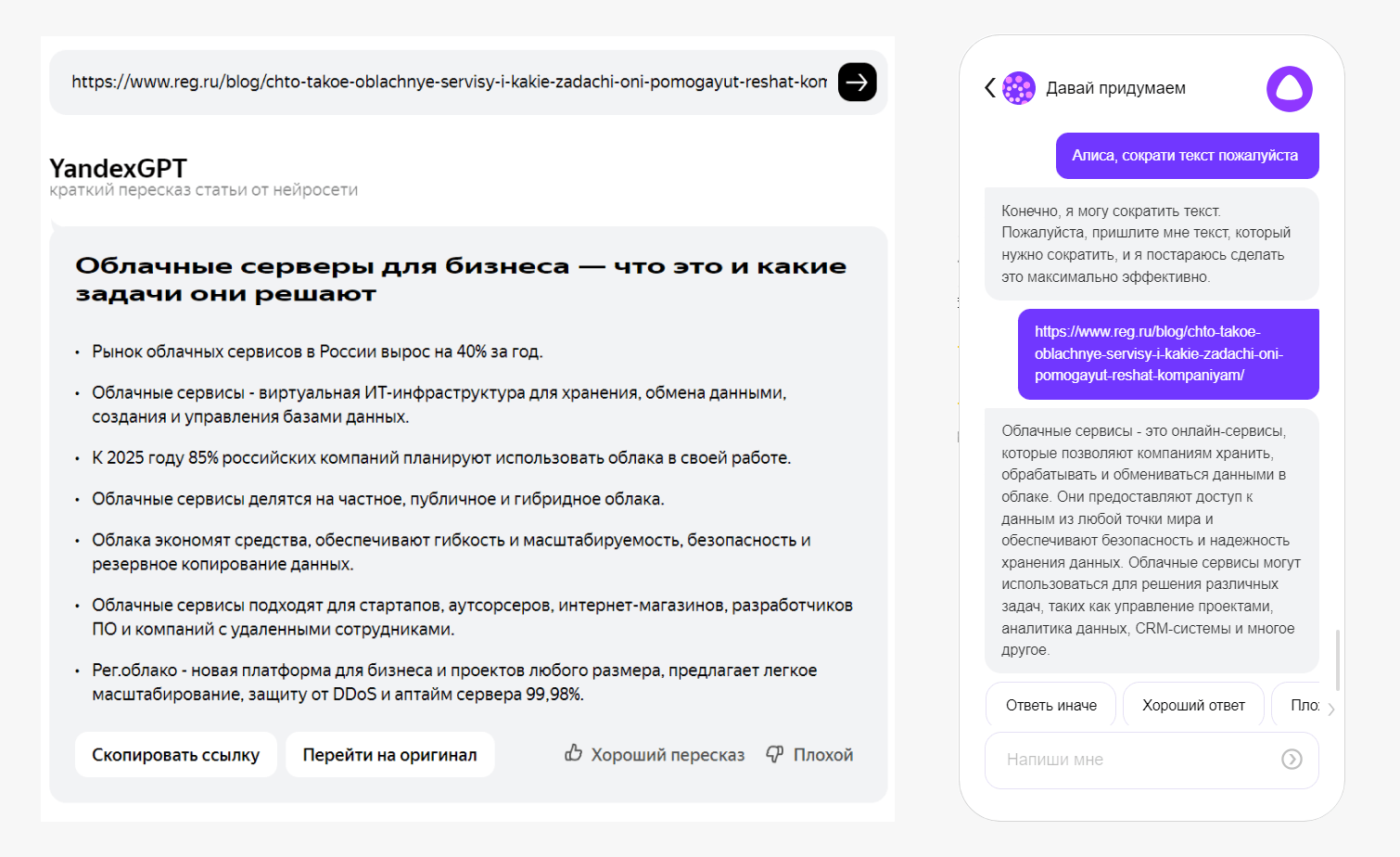
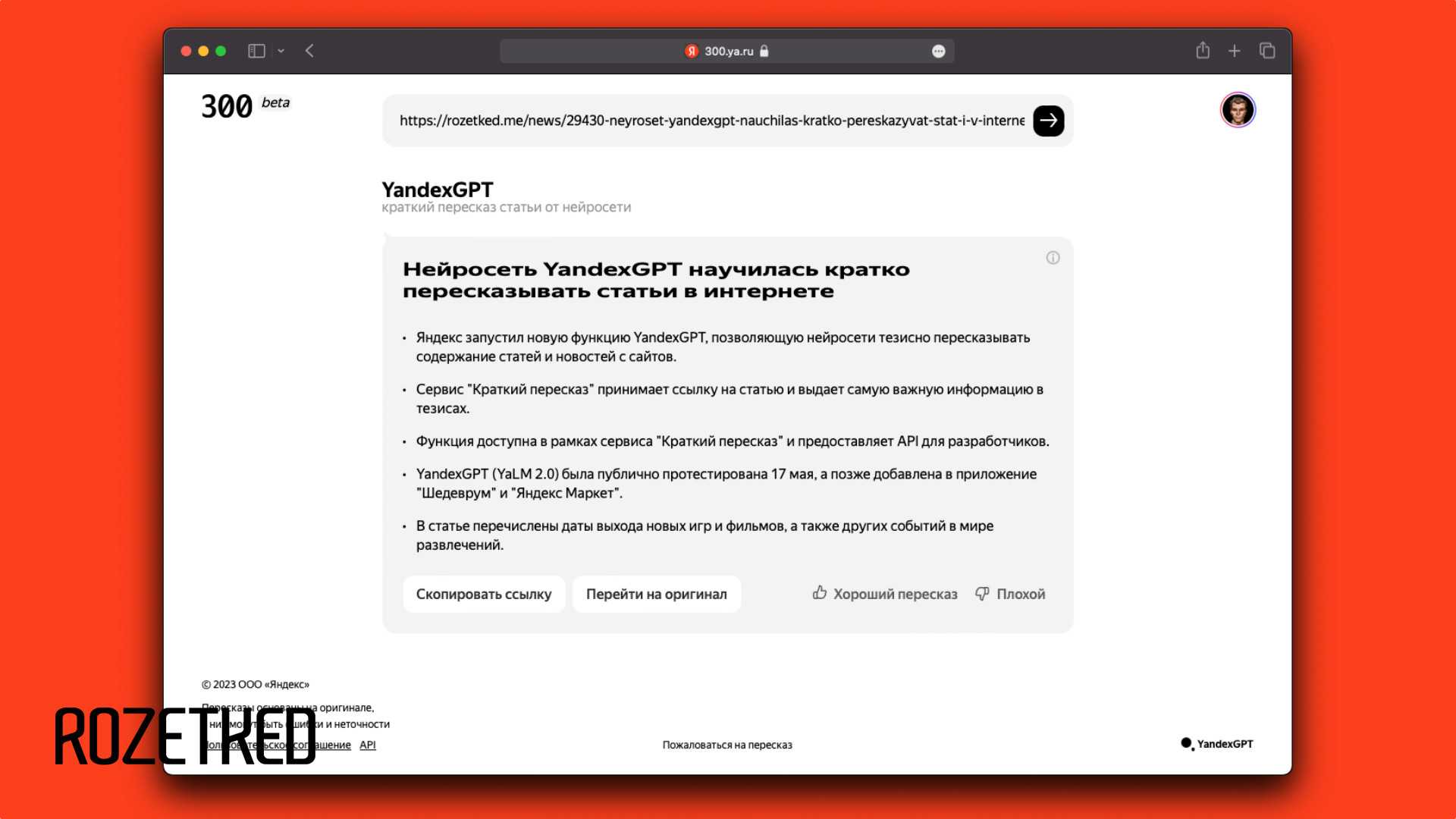
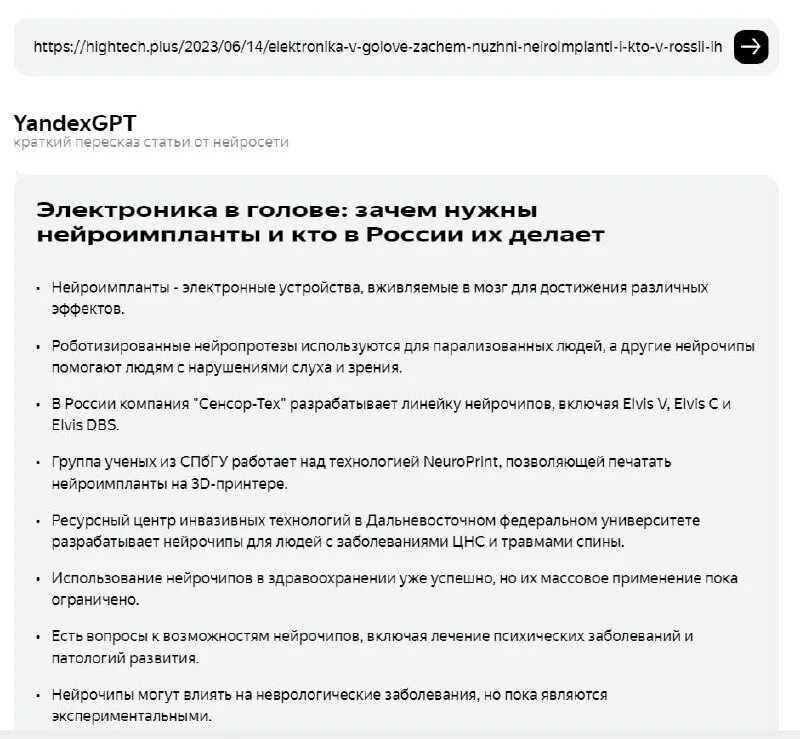
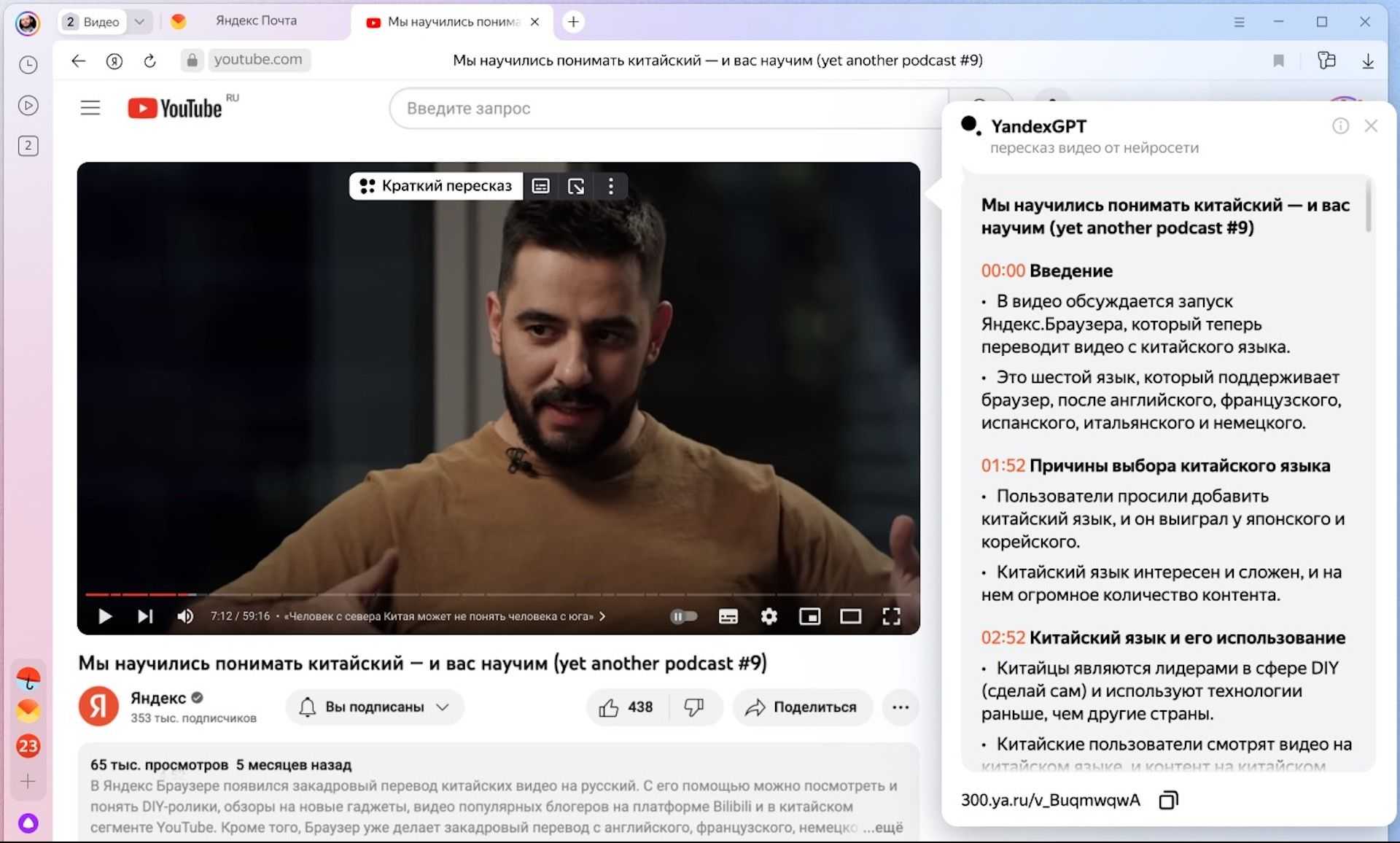
Кроме того, летом этого же года разработчики научили нейросеть пересказывать тексты, что в дальнейшем позволило задействовать ее для распознавания и краткого пересказа видеороликов с YouTube.
How is the article summarizing the tool works?
Our Text Summarizer uses AI-based algorithms to understand your content and then proceed for selecting the most appropriate sentences. The algorithms give the score to each of the sentences according to its optimization, selection of words, structure, and accuracy. According to the score, the tool understands the importance of these sentences where it can also find the sentences which is informative. Later, these informative and important sentences are gathers to make the summarized content. Later, the algorithms automatically proofread the writing and notice any error to remove.
Features:
Whether you want to summarize for educational career or official use, the Prepostseo’s Text Summarizer is very helpful. This is because this tool is accurate and efficient for making an overview of an article. Our Text Summarizer is developed with advanced algorithms that work to understand your content and then generate an overview of your written words. Remember, this tool doesn’t change the meaning of the actual content instead it just understands the whole content and finds the best overview. Here are some of the amazing features of this tool:
• Set Summarization Percent
This is not obvious that this summary generator would auto summarize the text in random lines instead you can set the percentage of the length of the summarized content. For example, if you want 50% of the summarized content then below this tool, you can use the feature of setting the required percentage. Between 0 and 100, you can easily select any number to get the content according to your requirements.
• Show in Bullets
This is a button below the tool that can help you to get the format according to your desire. When you are summarizing the content, clicking this button will make your result in the bullets. This is usually helpful when you have made a presentation and you want to convert this presentation into a quick overview for preparation.
• Show Ranking Wise
This feature helps you to make a sequence in your content according to the ranking. If the sentence is more optimized then it would get more ranking score. Through clicking this button, the result will generate the sequence from the highest scored sentence in the first position.
• Show the best sentence
The best sentence feature would tell you the sentence that has the highest score according to our algorithms. If you have written a lot of sentences and you want to get the best one then this feature is beneficial for you.
• Show top sentences
This is just like the best sentence but in more quantity. This option features the top sentences according to your required numbers. Once you check this option, you have to enter the number of sentences you need. Once you write, it will generate the top sentences according to the score of each sentence.
Быстрый взгляд на то, как GPT модели адаптируются по мере роста затрат на обучение
Однако конкретные важные навыки, как правило, возникают непредсказуемо как побочный продукт повышения квалификации. расходы на обучение (более длительное обучение, больше данных, большая модель) — почти невозможно предсказать, когда модели начнут выполнять те или иные задачи. Мы более подробно изучили эту тему в нашей гайд об истории развития GPT модели. На картинке показано распределение прироста качества моделей по разным задачам. Только большие модели могут научиться выполнять различные задачи. Этот график подчеркивает значительное влияние увеличения размера GPT Модели на их эффективность в различных задачах
Однако важно отметить, что это происходит за счет увеличения вычислительных ресурсов и воздействия на окружающую среду
Нет простого решения для управления LLM
Не существует надежных методов управления поведением LLM. Хотя был достигнут некоторый прогресс в понимании и смягчении различных проблем (включая ChatGPT и GPT-4 с помощью обратной связи), нет единого мнения, сможем ли мы их решить. Растет обеспокоенность, что в будущем, когда будут созданы еще более крупные системы, это станет огромной, потенциально катастрофической проблемой. Поэтому исследователи изучают новые методы, позволяющие обеспечить соответствие систем ИИ человеческим ценностям и целям, такие как согласование ценностей и разработка вознаграждений. Однако остается сложной задачей гарантировать безопасность и надежность LLM в сложных реальных сценариях.


| Прочитайте больше: OpenAI Собирает команду из 50+ экспертов для улучшения GPT-4безопасность |
Вы сделали это!
Это наиболее детальное описание блока Трансформера, в которое мы когда-либо пускались. Вы теперь имеете достаточно обширную картину того, что происходит внутри языковой модели Трансформера. Подводя итоги, покажем, как наш храбрый входной вектор взаимодействует с матрицами весов:
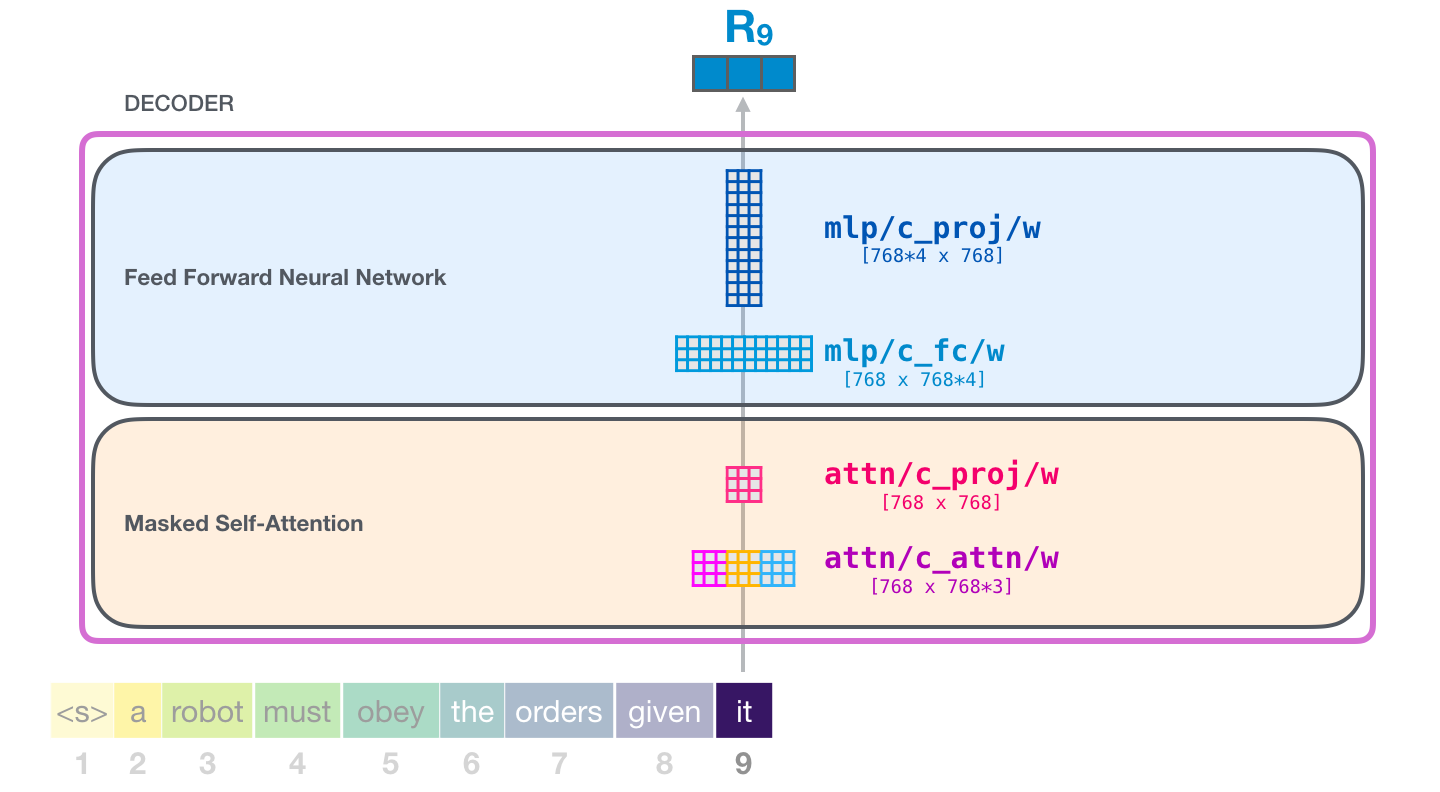
Каждый блок имеет свой собственный набор весов. С другой стороны, модель имеет только одну матрицу эмбеддинга токена и одну матрицу позиционного кодирования:
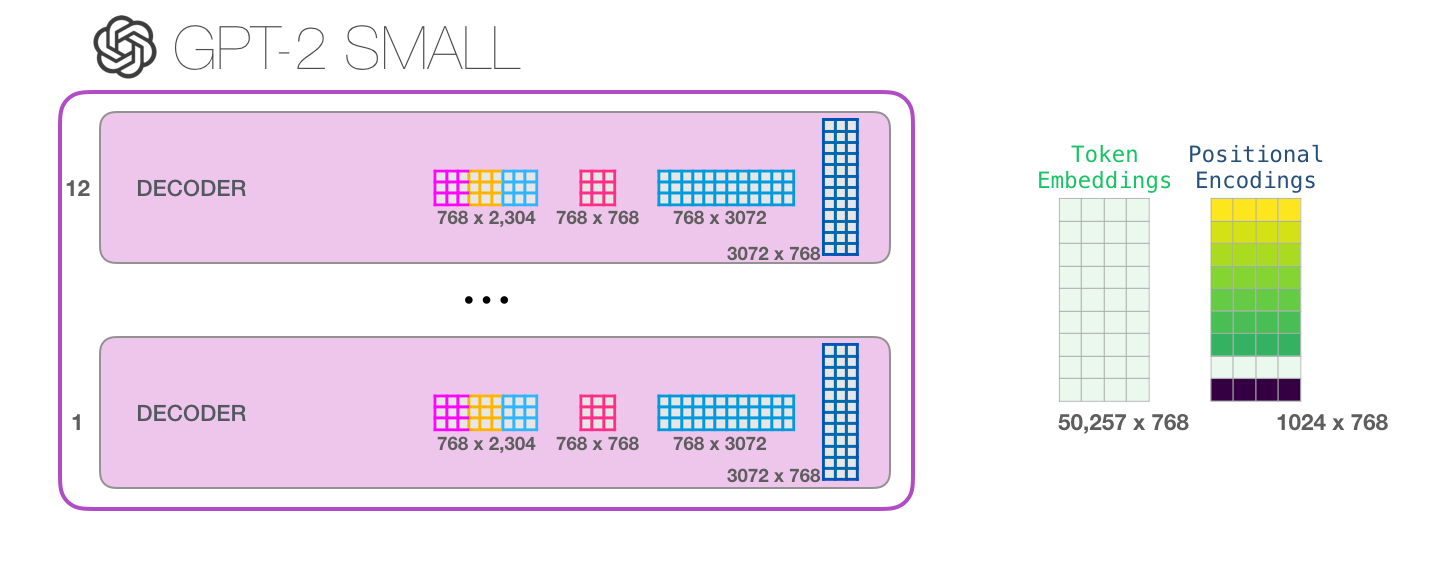
Если вы хотите увидеть все параметры этой модели, то они перечислены ниже:
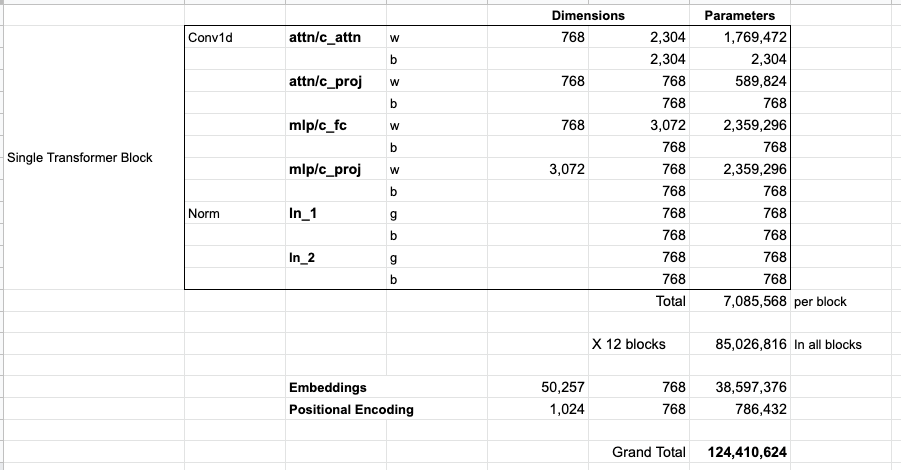
По какой-то причине здесь используется 124М параметров вместо 117М. Не вполне понятно почему, но кажется, что именно такое количество публикуется в открытом коде (поправьте, если это не так).
Часть 3: за пределами языкового моделирования
Декодирующие Трасформеры подают надежды и в задачах, отличных от языкового моделирования. Существует множество успешных применений этих моделей, которые можно визуализировать схожим образом. В завершение статьи посмотрим некоторые из этих применений.
Experiment #5: Providing my excerpts from the book
At this point, I’ve spent an hour reading very generic summaries of DeMarco’s ideas, and am honestly second guessing whether his book contains anything interesting at all. Maybe it’s not possible to generate the kind of summary I’m looking for because the book isn’t relevant to my needs in the first place.
I purposefully avoided reviewing my notes on the book up until this point to make my evaluations of ChatGPT’s output as neutral as possible, but now it’s time to dive in and see what it’s been missing.
I started by asking ChatGPT how many words I could fit in its “context window” – the word limit of how much text I can provide in my prompts. It estimated about 1,000 to 1,200 words. I wanted to keep this in mind as I summarized my own notes using my typical process, known as Progressive Summarization (basically an advanced form of highlighting).
Slack contains about 46,000 words, and my saved excerpts totaled 6,867 words, which meant I had saved about 15% of the original text as excerpts in my notes. I would need to select no more than 17% of that 15% (or about 2.5% of the entire book) to be able to feed into ChatGPT’s context window.
Обучение языковой модели
Чтобы языковая модель могла выдавать корректные и логично связанные между собой фразы, в нее нужно заложить огромное количество параметров: в GPT-3 их миллиардов. Процесс настройки параметров подобной модели называется ее обучением.
Для того чтобы модель умела связывать слова в предложения подобно людям, нужно показать ей большое количество реальных текстов. Например, та же GPT-3 обучалась на сотнях миллионов примеров из интернета и книг.
Процесс обучения языковой модели выглядит следующим образом. Мы берем какой-то кусочек текста и делим его на две части: основную и слово-продолжение, которое должно идти после нее. Предложенный выше пример мы можем разделить на основную часть «В школьной программе математики ученики изучают…» и слово-продолжение «алгебру».
После этого мы можем показать модели основную часть текста и попросить дополнить его
Обратите внимание, что корректное продолжение — слово «алгебру» — знаем только мы, но не модель

GPT-3 — одна из самых больших языковых моделей
Фото: TippaPatt / Shutterstock / FOTODOM
Необученная модель может генерировать некорректные продолжения фраз. Например, в нашем случае вместо слова «алгебру» она предложила бы, допустим, «литературу». В случае подобной ошибки мы можем настроить на конкретном примере параметры модели так, чтобы она предлагала более подходящее слово. В этом и заключается процесс обучения.
При таком объеме данных и количестве параметров обучение модели может занимать месяцы даже на мощнейших суперкомпьютерах. За это время она усваивает закономерности создания предложений из слов, запоминает факты об окружающем мире и приобретает «понимание» того, как формировать на их основе логичные тексты.

Чат-боты все еще ошибаются, но скоро смогут изменить мир
Читать
Создание и редактирование текста
Эволюция блока Трансформера
Блок энкодера
Первый – это блок энкодера:
Блок энкодера из релизной статьи Трансформера может принимать на вход последовательности ограниченной длины (например, 512 токенов). Если входная последовательность меньше этого ограничения, то мы можем просто заполнить остаток последовательности нулями.
Блок декодера
Второй – это блок декодера, который архитектурно мало отличается от энкодера
Он позволяет обращать внимание на особые сегменты энкодера:
Ключевая разница заключается в механизме работы слоя внутреннего внимания и состоит в том, что здесь будущие токены маскируются не заменой слова на токен, как в BERT’е, а с помощью изменения процесса подсчета внутреннего внимания и блокирования информации от токенов, находящихся справа от той позиции, которая высчитывается в данный момент.
Если, например, мы хотим подсветить траекторию позиции #4, мы можем увидеть, что можно обратиться лишь к этому и предыдущему токену:
Важно провести различие между внутренним вниманием, которое использует BERT, и маскированным внутренним вниманием GPT-2. Обычный блок внутреннего внимания позволяет достать до токенов справа. Маскированное внутреннее внимание не позволяет этого сделать:
Маскированное внутреннее внимание не позволяет этого сделать:
Блок декодирования
Блоки декодера идентичны. На развернутом изображении одного из них видно, что слой внутреннего внимания маскирован. Заметьте, что модель теперь может обращаться к 4000 токенов в отдельном сегменте – значительное улучшение по сравнению с 512 токенами оригинального трансформера.






Модель GPT-2 от OpenAI использует именно такие блоки декодирования.
Why use GPT-3 Text Summarization?
GPT-3 Text Summarization offers several benefits that make it a valuable tool for various applications:
1. Time-saving
Manually reading and summarizing lengthy texts can be time-consuming and labor-intensive.GPT-3 Text Summarization automates this process, allowing users to quickly obtain concise summaries without the need for extensive manual effort.
2. Information extraction
By condensing a large amount of text into a shorter summary, GPT-3 Text Summarization helps users extract the most important information from a document or article.This can be particularly useful when dealing with large volumes of data or when trying to gain insights from multiple sources.
3. Content curation
GPT-3 Text Summarization can assist in content curation by providing summaries of articles,blog posts, or research papers.This enables users to quickly assess the relevance and quality of the content, helping them make informed decisions about what to read or share.
Example where I’m using AtOnce’s AI review response generator to make customers happier:
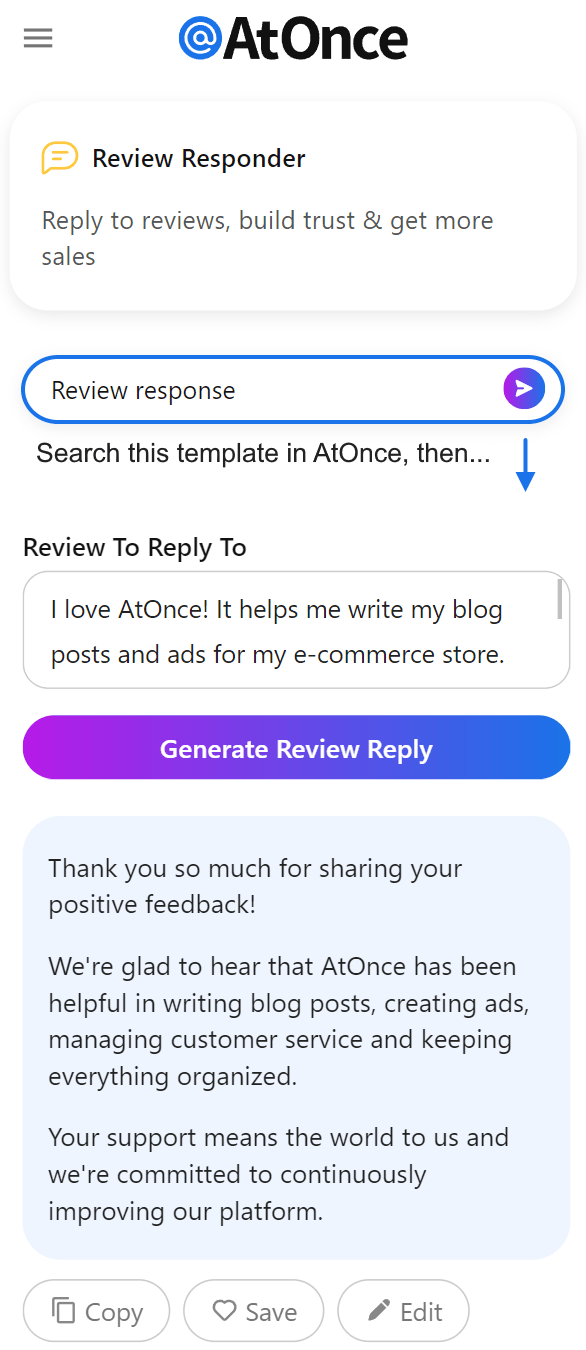
4. Language translation
GPT-3 Text Summarization can also be used for language translation purposes.By summarizing a text in one language and then translating the summary into another language, it can help bridge the language barrier and facilitate communication between different linguistic communities.
Challenges and limitations of GPT-3 Text Summarization
While GPT-3 Text Summarization offers many advantages, it also faces certain challenges and limitations:
1. Contextual understanding
GPT-3 Text Summarization relies on its contextual understanding of language to generate summaries.However, the model may not always grasp the full context or nuances of the text, leading to potential inaccuracies or misinterpretations in the generated summaries.
2. Length limitations
GPT-3 Text Summarization has limitations on the length of the input text it can effectively summarize.Extremely long texts may result in incomplete or truncated summaries, as the model may struggle to condense all the information into a concise format.
3. Domain-specific knowledge
GPT-3 Text Summarization may not possess domain-specific knowledge or expertise.When summarizing texts from specialized fields or technical subjects, the model may struggle to accurately capture the intricacies and nuances unique to those domains.
4. Bias and subjectivity
Like any NLP model, GPT-3 Text Summarization can be influenced by biases present in the training data.This can result in summaries that reflect or amplify certain biases, potentially leading to skewed or incomplete representations of the original text.
LLM более «способны», поскольку затраты продолжают расти
LLM предсказуемо становятся более «способными» с ростом затрат, даже без крутых инноваций. Здесь главное предсказуемость, что и было показано в статье про GPT-4: обучалось пять-семь маленьких моделей с бюджетом 0.1% от итоговой, а затем на основе этого делался прогноз для огромной модели. Для общей оценки недоумения и метрик на подвыборке одной конкретной задачи такой прогноз оказался очень точным. Эта предсказуемость важна для предприятий и организаций, которые полагаются на LLM в своей деятельности, поскольку они могут соответствующим образом составлять бюджет и планировать будущие расходы
Тем не менее, важно отметить, что, хотя увеличение затрат может привести к улучшению возможностей, скорость улучшения может в конечном итоге стабилизироваться, что делает необходимым вложение средств в новые инновации для продолжения развития
расширения
В этом разделе перечислены некоторые идеи по расширению учебника, которые вы, возможно, захотите изучить.
- набивка, Обновите пример, предоставляя последовательности построчно, и используйте заполнение, чтобы заполнить каждую последовательность до максимальной длины строки.
- Длина последовательности, Поэкспериментируйте с различными длинами последовательностей и посмотрите, как они влияют на поведение модели.
- Модель мелодии, Поэкспериментируйте с различными конфигурациями моделей, такими как количество ячеек памяти и эпох, и попытайтесь разработать лучшую модель для меньшего количества ресурсов.
Benefits of using an online Text Summarizer
Now, there is no need to read the entire document to get the main ideas from it.The summarizing tool works quickly and provides you with important data within a blink of an eye.
When you are searching for some important information from an article on the web, it takes both time and effort.This tool increases your productivity by quickly providing a summary of the input text.
The summarization tool helps students instantly find the summary of their lengthy essays and other academic work.It helps them to easily summarize their assignments and notes without any hurdles.
Our summarize tool helps you to skim the important text without performing the skimming process.It also helps you to review the large content within a fraction of a second.